
- Introduction
- Model-Specific Observations
- Conclusion
Introduction
In the first post of this series, we explored general process insights gained from a year of intensive work with Large Language Models (LLMs). We discussed the importance of context, the power of iterative refinement, and the shift in creative processes that LLMs have brought about. These insights laid the groundwork for understanding how LLMs are changing our approach to complex tasks, particularly in legal and business contexts.

As we continue our exploration, this second post focuses on model-specific observations. Over the past year, we’ve seen notable advancements in LLM capabilities, from the introduction of powerful vision models to the emergence of highly capable “mini” models. We’ve also witnessed the expansion of context windows and the refinement of top-tier models like GPT-4 and Claude 3.5 Sonnet.
In this post, we’ll look into four key areas:
- The arrival of capable vision models and their potential applications
- GPT-4o and Claude 3.5 Sonnet as solid foundations for complex tasks
- The unexpected utility of mini models in specific use cases
- The opportunities and challenges presented by long context windows
These observations are valuable for anyone working with or planning to implement LLMs in their workflows. Understanding the strengths, limitations, and optimal use cases for different models can help you make more informed decisions about which tools to use and how to use them effectively.
Let’s dive into these model-specific insights and explore how they can shape our approach to leveraging LLMs in legal and business contexts.
Model-Specific Observations
The Arrival of Capable Vision Models
Over the past year, we’ve seen a notable advancement in LLM technology with the integration of vision capabilities (officially Large Vision Models – LVMs – but I’ll assume LLMs include LVMs). Models like GPT-4o (previously GPT4 – Vision) and Claude 3.5 Sonnet can now process and understand visual information alongside text, opening up new possibilities for AI applications.
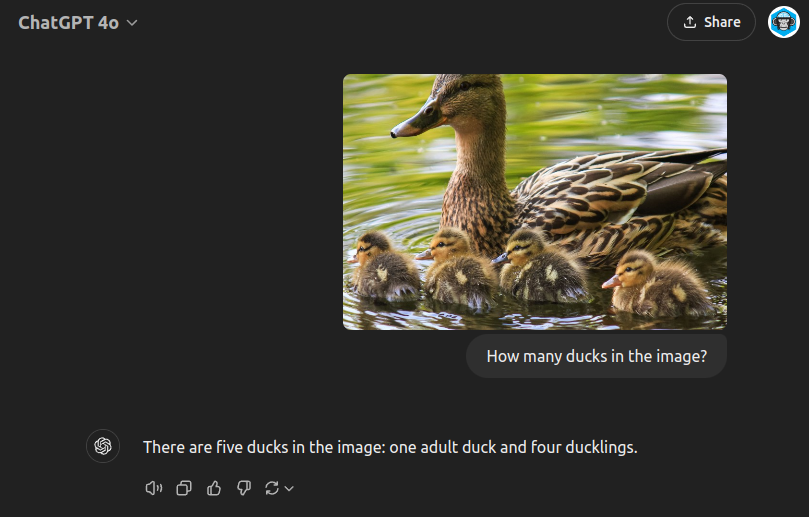
These models can analyse images, answer questions about visual content, and even count objects within images. Implementing vision capabilities requires some adjustments to classic text pipelines. For example, API requests need tweaking to provide image as well as text data, with the possibility of interleaving the two. Practically images are provided as base64 encoded strings or via URLs. For those interested in implementation details, both OpenAI and Anthropic provide comprehensive documentation.
While many organisations are still focused on text-based LLM integration, vision models offer exciting possibilities:
- Document Analysis: Extracting information from forms, diagrams, or handwritten notes.
- Visual Compliance Checks: Identifying safety violations or non-compliant elements in images.
- Enhanced Legal Research: Analysing visual evidence or diagrams in patent applications.
Looking ahead, technologies like ColPali, which combines vision and language models for document retrieval, show promise for improving how we search and analyse visual information in documents. Additionally, specialised models like YOLO (You Only Look Once – we’re onto version 2 3) for object detection and SAM2 (Segment Anything Model 2) for image segmentation offer potential for more nuanced understanding of visual content, though their integration into business processes is still in early stages. For example, we are missing mature real-time libraries for rapid image evaluations.

Despite their potential, vision models do present challenges, including increased computational requirements, new privacy considerations for visual data, and the need for human oversight to ensure accuracy and reliability.
The integration of vision capabilities into LLMs represents a significant step forward. As these technologies mature, we can expect to see innovative applications across multiple industries, including law and business. However, it’s worth noting that many organisations are still in the early stages of exploring these capabilities, with text-based applications remaining the primary focus for now.
GPT4o and Claude 3.5 Sonnet: Solid Foundations for Complex Tasks
Over the past year, we’ve witnessed significant advancements in large language models, with GPT4o and Claude 3.5 Sonnet emerging as robust foundations for complex tasks in various domains, including law and business.

Evolution and Current Capabilities
GPT4o (OpenAI)
- Released on May 13, 2024, as part of the GPT-4 family
- Key feature: Incorporation of vision functionality (multimodal capabilities)
- Context window: 128,000 tokens
- Performance: Faster than GPT-4 Turbo, generally more stable
- Qualitative assessment: Capabilities between GPT-4 and GPT-4 Turbo, suitable for most GPT-4 use cases
- Current pricing (as of October 2024): $2.50 / 1M input tokens, $10.00 / 1M output tokens
Claude 3.5 Sonnet (Anthropic)
- Released on June 20, 2024, as an upgrade to the Claude 3 family
- Context window: 200,000 tokens
- Key improvements: Enhanced coding abilities, multistep workflows, and image interpretation
- Notable feature: Introduction of Artifacts for real-time code rendering
- Extended output capability: Up to 8,192 tokens (as of August 19, 2024)
- Current pricing (as of October 2024): $1.25 / 1M input tokens, $5.00 / 1M output tokens
History
The development of these models represents a rapid evolution in AI capabilities. Here’s a brief timeline of key milestones:
OpenAI’s GPT Series:
- March 15, 2022: GPT-3.5 released (as “text-davinci-002” and “code-davinci-002”)
- March 14, 2023: GPT-4 released (with initial waitlist)
- November 6, 2023: GPT-4 Turbo introduced, featuring 128K context window
- May 13, 2024: GPT4o (Omni) released, incorporating vision functionality
- September 2024: o1 Series Preview released (o1-preview, o1-mini)
Anthropic’s Claude Series:
- March 2023: Claude 1 API launched
- July 2023: Claude 2 released, with 100K token context window
- November 2023: Claude 2.1 released, expanding context to 200K tokens
- March 14, 2024: Claude 3 family (Haiku, Sonnet, Opus) released
- June 20, 2024: Claude 3.5 Sonnet released, with improved coding and image interpretation
- August 19, 2024: Extended output (8,192 tokens) for Claude 3.5 Sonnet made generally available
This timeline illustrates the rapid pace of development in large language models, with both OpenAI and Anthropic consistently increasing context sizes, improving performance, and introducing new capabilities such as vision processing and extended output generation.
The rapidly developing oligopoly is good for consumers and businesses, driving the conversion of venture capital cash into useful feature development.
Practical Applications
Both models (GPT4o and Claude 3.5 Sonnet) are effective for generating professional level output. There is still a bias to an American, online-marketing influenced enthusiasm but this can often been eliminated via careful prompting.
Both models are capable of generating working small code projects (with Claude 3.5 having the slight edge) and, via an iterative chat, of generating good enough content for standard Internet publishing (this blog series is generated in collaboration with Claude 3.5). Neither model is ready to be left alone to output content without careful human checking though. Their fluency with words often hides a shallowness of information content. This can be addressed to a certain extent in providing high quality “first draft” information and good context. But “garbage in, garbage out” still reigns.
For example, both models are capable of writing competent sounding business letters and emails. In terms of reasoning abilities, they can probably meet the level of “average, half-awake, mid-tier, business manager, graduate”, especially if all the content needed for the reasoning is available in the prompt and there are clearly defined action possibilities. They are likely able to as a secretarial first-instance response generator to be checked / changed / regenerated by a human in the loop.
Later on in the post series we’ll look in more detail at the current limitations of these models for legal applications.
While these models provide powerful capabilities, it’s crucial to remember that human oversight remains necessary, especially for high-stakes tasks. The value of GPT4o and Claude 3.5 Sonnet lies in augmenting human intelligence, offering rapid information processing and idea generation.
At present model development has been rather quicker than development capacity to really build systems around them. Just last summer (August 2023) it appeared that progress had stalled with GPT-4, but Claude coming online and continued rapid model evolution means we are coming to expect jobs in capability every 6 months or so. Indeed, Claude Opus 3.5 – their higher specification model – is still to be released.
As we continue working with these models, we’re constantly discovering new applications, in turn pushing the boundaries of AI-assisted professional work. The rapid evolution of these models, as evidenced by their release timelines, suggests that we can expect further improvements and capabilities in the near future.
The Unexpected Utility of Mini Models
As discussed briefly in our first post, mini models have emerged as surprisingly capable tools for specific tasks within complex workflows. These models, designed for speed and efficiency, offer a balance between performance and cost that opens up new possibilities for AI integration in various fields.

Key Mini Models
GPT-4o mini (OpenAI)
- Link: https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/
- Release date: July 18, 2024
- Context window: 128,000 tokens
- Key features:
- Scores 82% on MMLU (Massive Multitask Language Understanding)
- Supports text and vision inputs
- Knowledge cutoff up to October 2023
- Supports up to 16,384 output tokens per request
- Improved tokenizer for more cost-effective handling of non-English text
- Strong performance in function calling and long-context tasks
- Pricing:
- Input: $0.15 per million tokens
- Output: $0.60 per million tokens
- Over 60% cheaper than GPT-3.5 Turbo
Claude 3 Haiku (Anthropic)
- Link: https://www.anthropic.com/news/claude-3-haiku
- Release date: March 14, 2024
- Context window: 200,000 tokens
- Key features:
- Fastest model in the Claude 3 family, processing 21K tokens (~30 pages) per second for prompts under 32K tokens
- Strong performance on industry benchmarks (MMLU score of 0.752)
- State-of-the-art vision capabilities
- Designed for rapid analysis of large datasets
- Three times faster than peers for most workloads
- Optimized for enterprise-grade security and robustness
- Pricing:
- Input: $0.25 per million tokens
- Output: $1.25 per million tokens
Gemini 1.5 Flash (Google)
- Link: https://developers.googleblog.com/en/gemini-15-flash-8b-is-now-generally-available-for-use/
- Release date: May 24, 2024 (initial version gemini-1.5-flash-001)
- Context window: 1 million tokens
- Key features:
- Optimized for narrower or high-frequency tasks where response time is crucial
- Natively multimodal, supporting text, images, audio, and video inputs
- Improved performance for tasks like chat, transcription, and long context language translation
- Supports adding image, audio, video, and PDF files in text or chat prompts
- JSON mode support (added August 30, 2024)
- Pricing:
- 50% lower price compared to the previous 1.5 Flash model
- Described as having the “lowest cost per intelligence of any Gemini model”
Characteristics and Use Cases
These mini models are designed for real-time interaction, embodying a “System 1” thinking style – quick and generally accurate, but potentially prone to errors. Their cost-effectiveness for high-volume requests makes them particularly suitable for tasks that require rapid processing of large amounts of data.
While Claude 3.5 Sonnet and GPT4o are around the $1-1.5 per million tokens, these models are between 3-25% of the cost. GPT4o-mini is about 15c (10p-ish) for a million tokens and Gemini Flash is even cheaper at 3-4c (2-3p-ish).
One standout feature is their effectiveness in “needle in a haystack” information retrieval. Models like Gemini 1.5 Flash, with its massive 1 million token context window, can process entire movies or document libraries in a single pass, making it ideal for tasks that involve sifting through large volumes of unstructured data. For example, in litigation if you needed to trawl through video, looking for when a particular person came on screen or trying to find when a particular event occurred, sticking it into Gemini Flash is a no-brainer. Even if it is wrong it could save hours of human effort.
Potential Applications
- Format translation (e.g., generating JSON from text)
- Non-mathematical analysis tasks
- Real-time chat and customer service applications
- Rapid document classification and information extraction
- Initial data preprocessing for more complex AI pipelines
Limitations in Legal Work
Despite their impressive capabilities, we’ve found these mini models to have limited applications in generative legal work. The primary concerns are:
- Reliability: They are often too unreliable for even short content generation in legal contexts, where accuracy is paramount. It feels a bit like asking a teenager.
- Cost considerations: In legal practice, the budget often allows for using more robust, albeit more expensive, models. The potential cost savings from mini models are outweighed by the need for precision.
- Analysis time: Legal work often involves longer, more thorough analysis, which aligns better with the capabilities of more comprehensive models.
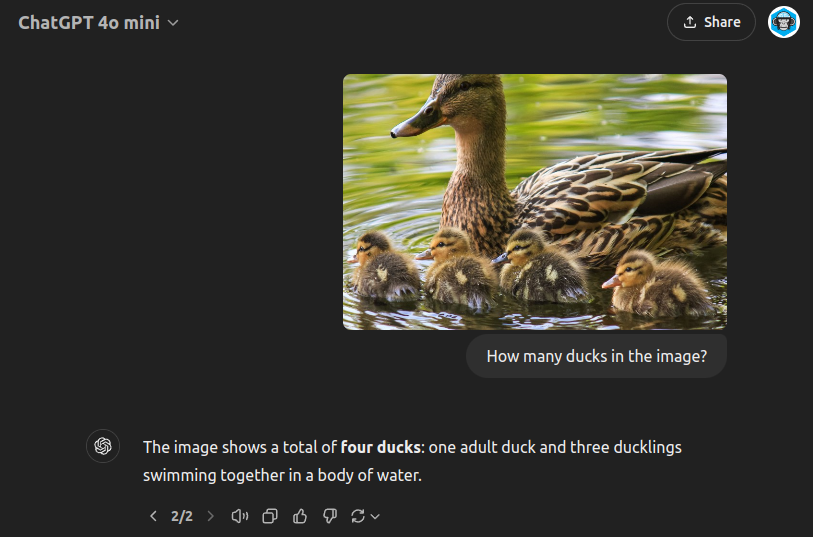
However, these models may still find utility in “under-the-bonnet” grunt work tasks within legal workflows, such as initial document sorting or basic information extraction.
Mini models represent an intriguing development in the AI landscape. While they may not be suitable for all aspects of legal work, their speed, efficiency, and cost-effectiveness open up new possibilities for AI integration in various fields. As these models continue to evolve, we may see them taking on increasingly sophisticated roles in complex workflows, complementing rather than replacing their larger counterparts.
Long Contexts: Opportunities and Challenges
The past year has seen a remarkable evolution in the context handling capabilities of large language models. Just a year ago, most models were limited to around 8,000 tokens of input. Now, we’re seeing context windows ranging from 128,000 tokens (as in GPT4o) to 200,000 tokens (Claude 3.5 Sonnet), and even up to 1 million tokens in some mini models like Gemini 1.5 Flash.
Rapid Evolution
This rapid expansion of context windows has opened up new possibilities for AI applications:
- Whole Document Analysis: Models can now process entire documents, books, or even small databases in a single pass.
- Complex Multi-Step Reasoning: Longer contexts allow for more nuanced, multi-stage problem-solving within a single prompt.
- Enhanced Information Retrieval: The ability to search for and synthesize information across vast amounts of text has dramatically improved.
Current State of Long Contexts
- GPT4o: 128,000 tokens
- Claude 3.5 Sonnet: 200,000 tokens
- Mini Models: 128,000 to 1 million tokens (e.g., Gemini 1.5 Flash)
This expansion allows for processing of hundreds of pages of text in a single API call, a capability that was unthinkable just a year ago. GPT4o and Claude 3.5 can also have a mixture of text and images, and Gemini 1.5 Flash can ingest whole videos.
Opportunities
- Legal Document Review: Analyzing entire contracts or legal cases in context.
- Research Synthesis: Combining and summarizing large volumes of academic papers or reports.
- Content Creation: Generating long-form content with consistent themes and references throughout.
- Data Analysis: Processing and interpreting large datasets in a single pass.
- Patent Prosecution Analysis: An average patent is around 32K-50K tokens. Thus you can theoretically include 4-8 items of prior art in a prompt. This is roughly the amount of cited art in a patent office action.
- Patent Family Analysis: You could fit a medium-sized family into Gemini’s context window to ask specific simple questions of the family (e.g., is a feature described? where?). I’d be a bit skeptical of the response but it would be good as a first stage.
- A combination of RAG and prompt: RAG was often a solution to the small 4K input context window. It might still be useful as part of a hybrid approach. This could include RAG vector search, BM25 search, and raw LLM review, followed by reranking and reference citing.
Challenges
- Computational Costs: Processing such large contexts can be computationally expensive and time-consuming.
- Relevance Dilution: With more context, models may struggle to focus on the most relevant information.
- Consistency Across Long Outputs: Maintaining coherence and consistency in very long generated texts can be challenging.
- Memory Limitations: Even with long input contexts, models can sometimes “forget” earlier parts of the input in their responses.
In practice, I’ve found that you can’t completely trust the output of the models. When modelling a prior art review, both models sometimes got confused between a “claim 1” under review and a “claim 1” as featured in a patent application dumped into the context. I’ve also had it miss simple answers to some questions depending on the sample – e.g. in 1 in 5 runs.
It seems to have promise as part of a traceable and reviewable analysis trail, whereby a human is needed to check the answer and the citation before confirming and moving onto a next stage of review.
The Output Context Limitation
While input contexts have grown dramatically, output contexts remain more limited, typically ranging from 4,000 to 8,000 tokens. This limitation presents a challenge for generating very long documents or responses. To address this, developers and users often need to implement iterative approaches:
- Chunked Generation: Breaking down large document generation into smaller, manageable pieces.
- Summarisation and Expansion: Generating a summary first, then expanding on each section iteratively.
- Context Sliding: Moving a “window” of context through a large document to generate or analyse it piece by piece.
- Keeping Track: While generating a small section of the document, keep the other portions of the document being generated, and any relevant information for the small section in the prompt. This is possible with the larger contexts.
Further Work
The advent of long context models represents a significant leap forward in AI capabilities. However, it also brings new challenges in terms of effective utilisation and management of these vast input spaces. The development on the model side has iterated so quickly I’ve found that many developers are caught out a bit, having built systems for limited capabilities, yet finding the goal posts moving rapidly.
Conclusion
As we reflect on the developments in LLMs over the past year, it’s rather striking how quickly the landscape has evolved. From the emergence of capable vision models to the unexpected utility of mini models, and the expansion of context windows, we’ve seen a flurry of advancements that most of the technology world is struggling to keep up with.

The solid foundations provided by models like GPT4o and Claude 3.5 Sonnet offer glimpses of what might be possible in fields such as law and business. Yet, it’s important to remember that these tools, impressive as they may be, are not without their limitations. The challenges of consistency, reliability, and the need for human oversight remain ever-present.
The rise of mini models and the expansion of context windows present intriguing opportunities, particularly in tasks requiring rapid processing of vast amounts of information. However, one ought to approach these developments with a measure of caution, especially in fields where accuracy and nuance are paramount.
In the coming posts, we’ll delve deeper into the technical aspects of implementing these models and explore some of the persistent challenges that we’ve encountered. For now, we’re still very much in the early stages of understanding how best to harness these powerful tools.

One thought on “Key Insights from a Year of Working with LLMs (2/4)”