
I have been playing with natural language processing.
Now I have a body of patent data (see here), I can do some interesting things. For example, most people would say that patents have a pretty specific terminology. I say: show me the data.
Taking all patent publications in 2001 as an example, I programmed a little routine that:
- Extracted the text data of each patent publication;
- Split the text data into words;
- Filtered the words for non-words (e.g. punctuation etc.);
- Applied a stemming algorithm (from 1979!); and
- Recorded the frequency distribution of the results.
In total I counted 277493492 occurrences of 287455 unique word stems.
In common with most written material, 100 words accounted for 50% of the published material. Amazing when you think about it.
(Next time you get a drafting bill from a patent attorney, complain that half their work is shuffling 100 words around :)).
Here is the graph (click to zoom for full glory).
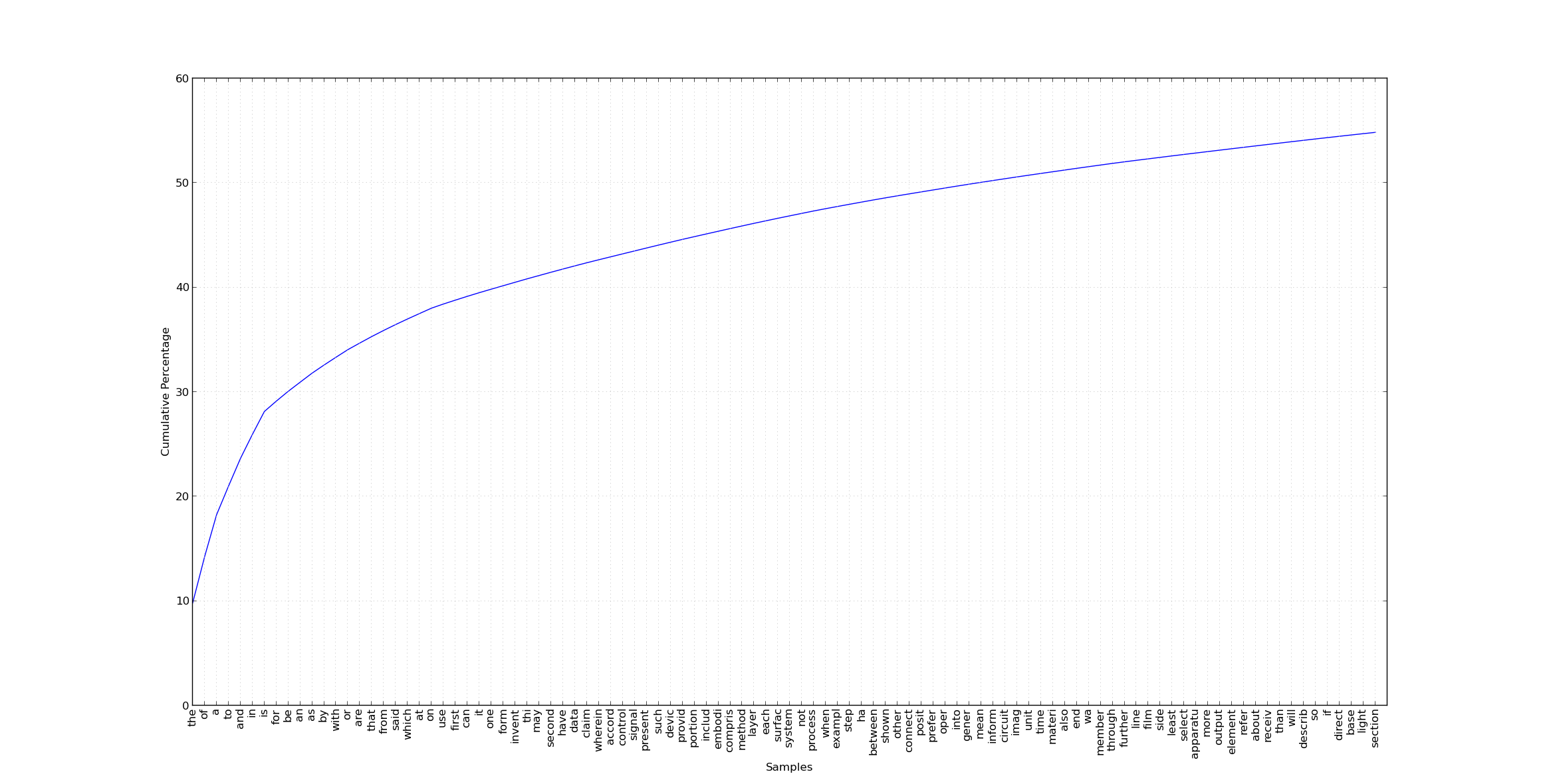
Patent Stopwords
There is more.
“Stopwords” are common words that are often filtered out when analysing documents. The Natural Language Tool Kit provides a set based on a general analysis of written English. These include words such as:
…’did’, ‘doing’, ‘a’, ‘an’, ‘the’, ‘and’, ‘but’, ‘if’, ‘or’, ‘because’, ‘as’, ‘until’, ‘while’, ‘of’, ‘at’, ‘by’, ‘for’…
In total there are 127 stopwords in this collection representing high-frequency content that has little lexical use.
I thought it would be interesting to compare these stopwords with the 127 most frequent in our frequency count.
Words that occurred frequently in (US) patent publications that do not comprise regular stopwords include:
said use first one form invent thi may second data claim wherein accord control signal present devic provid portion includ embodi compris method layer surfac system process exampl step ha shown connect posit prefer oper gener mean inform circuit imag unit time materi also end wa member line film side least select apparatu output element refer receiv describ direct base light section set show substrat contain display view valu part cell two plural group structur number optic electrod input result abov respect region memori plate case differ user
These words will be familiar to most patent professionals. The result of the stemming operation can be seen in certain words, e.g. “oper” – these should be treated as “oper*” – “operates”, “operating”, “operate” etc.. You can see that stemming is not perfect (“thi” may relate to “this”, which has been taken to be a plural form) but it is generally good enough. Without the stemming there would be many different variations of the same word in our counts.
Now this list of “patent stopwords” is useful. Firstly, these words are probably not useful for searching in isolation (we may move onto n-grams later). Secondly, they can be used as a dictionary of sorts for claim drafting. Thirdly, they could be used to distinguish patent text from non-patent text (e.g. as the basis for a feature vector for this classification).
The words that occur in patent specifications but also occur in “the real world” are also interesting:
the of a to and in is for be an as by with or are that from which at on can it have such each not when between other into through further more about than will so if then
These can be used as universal stopwords.
Further Fun
There are a number of paths for further analysis:
- Extend across the whole US patent publication corpus from 2001 to 2014. I may need to optimise my code to do this!
- Perform a similar analysis for different classification levels – e.g. do patents classified as G have a different vocabulary from those classified as H?
- Look at infrequent or unique words – How many are there? Are they useful for searching clusters?
