
We all are told that Large Language Models (LLMs) such as ChatGPT are prone to “hallucinations”. But did you know we can build systems that actively help to reduce or avoid this behaviour?
In this post, we’ll be looking at build a proof-of-concept legal Retrieval-Augmented Generation (RAG) system. In simple terms, it’s an LLM generative system that cites sources for its answers. We’ll look at applying it to some UK patent legislation.
(Caveat: I have again used GPT-4 to help with speeding up this blog post. The rubbish bits are its input.)
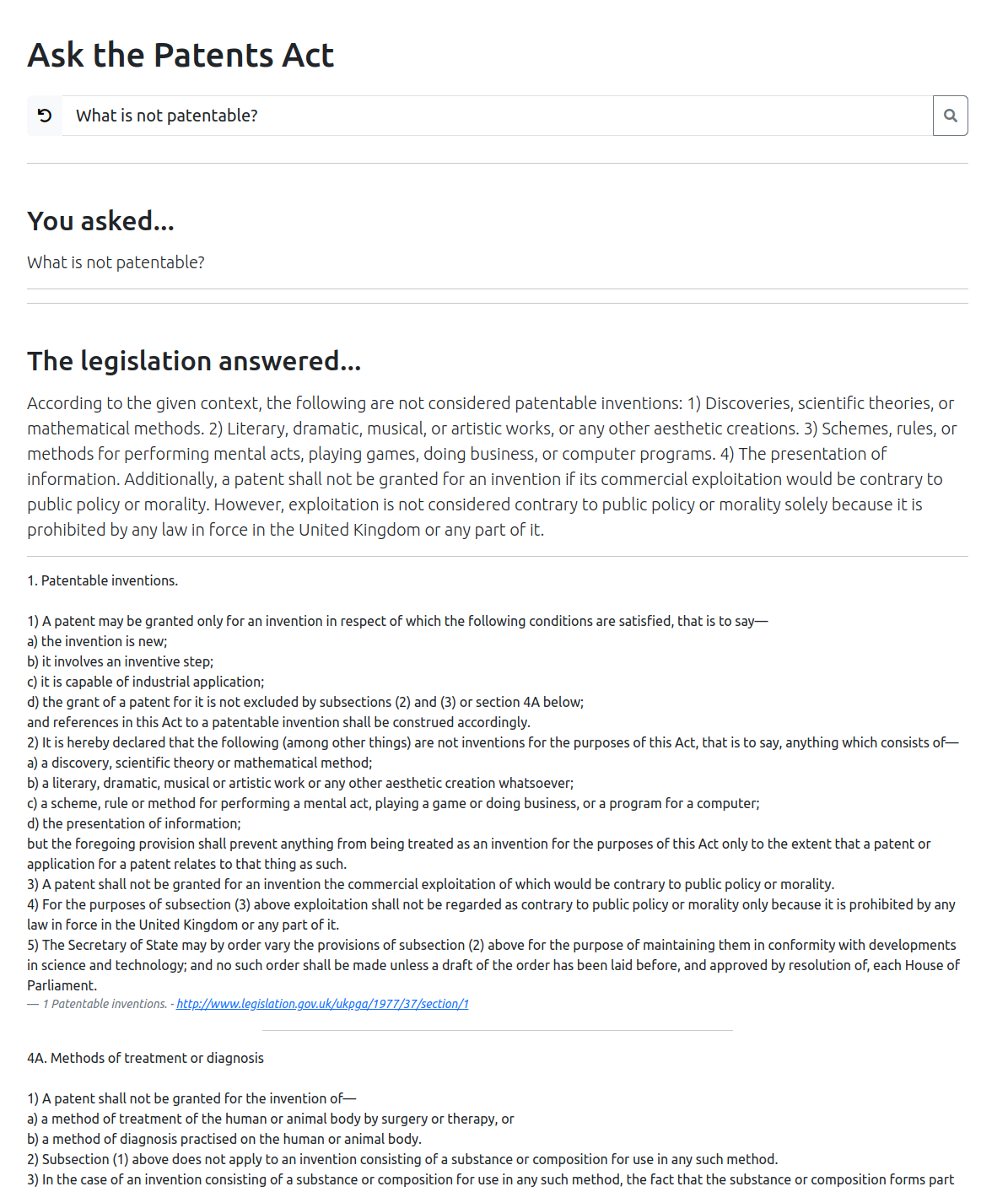
Scroll down to the bottom if you want to skip the implementation details and just look at the results.
If you just want to have a look at the code, you can find that here: https://github.com/Simibrum/talking_legislation
Introduction
The complex and often convoluted nature of legislation and legal texts makes them a challenging read for both laypeople and professionals alike. With the release of highly capable LLMs like GPT-4, more people have been using them to answer legal queries in a conversational manner. But there is a great risk attached – even capable LLMs are not immune to ‘hallucinations’ – spurious or inaccurate information.
What if we could build a system that not only converses with us but also cites its sources?
Enter Retrieval-Augmented Generation (RAG), a state-of-the-art technology that combines the best of both worlds: the text-generating capabilities of LLMs and the credibility of cited sources.
Challenges
Getting the Legislation
The first hurdle is obtaining the legislation in a format that’s both accurate and machine-readable.
Originally the official version of a particular piece of legislation was the version that was physically printed by a particular authority (such as the Queen or King’s printers). In the last 20 years, the law has mostly moved onto PDF versions of this printed legislation. While originally digital scans, most modern pieces of legislation are available as a digitally generated PDF.
PDF documents have problems though.
- They are a nightmare to machine-read.
- Older scanned legislation needs to be converted into text using Optical Character Recognition (OCR). This is slow and introduces errors.
- Even if we have digital representations of the text within a PDF, these representations are structured for display rather than information extraction. This makes it exceedingly difficult to extract structured information that is properly ordered and labelled.
Building the RAG Architecture
Implementing a RAG system is no small feat; it involves complex machine learning models, a well-designed architecture, and considerable computational resources.
Building a Web Interface
The user experience is crucial. A web interface has to be intuitive while being capable of handling the often lengthy generative timespans that come with running complex models.
Solutions
Using XML from an Online Source
In the UK, we have the great resource: www.legislation.gov.uk.
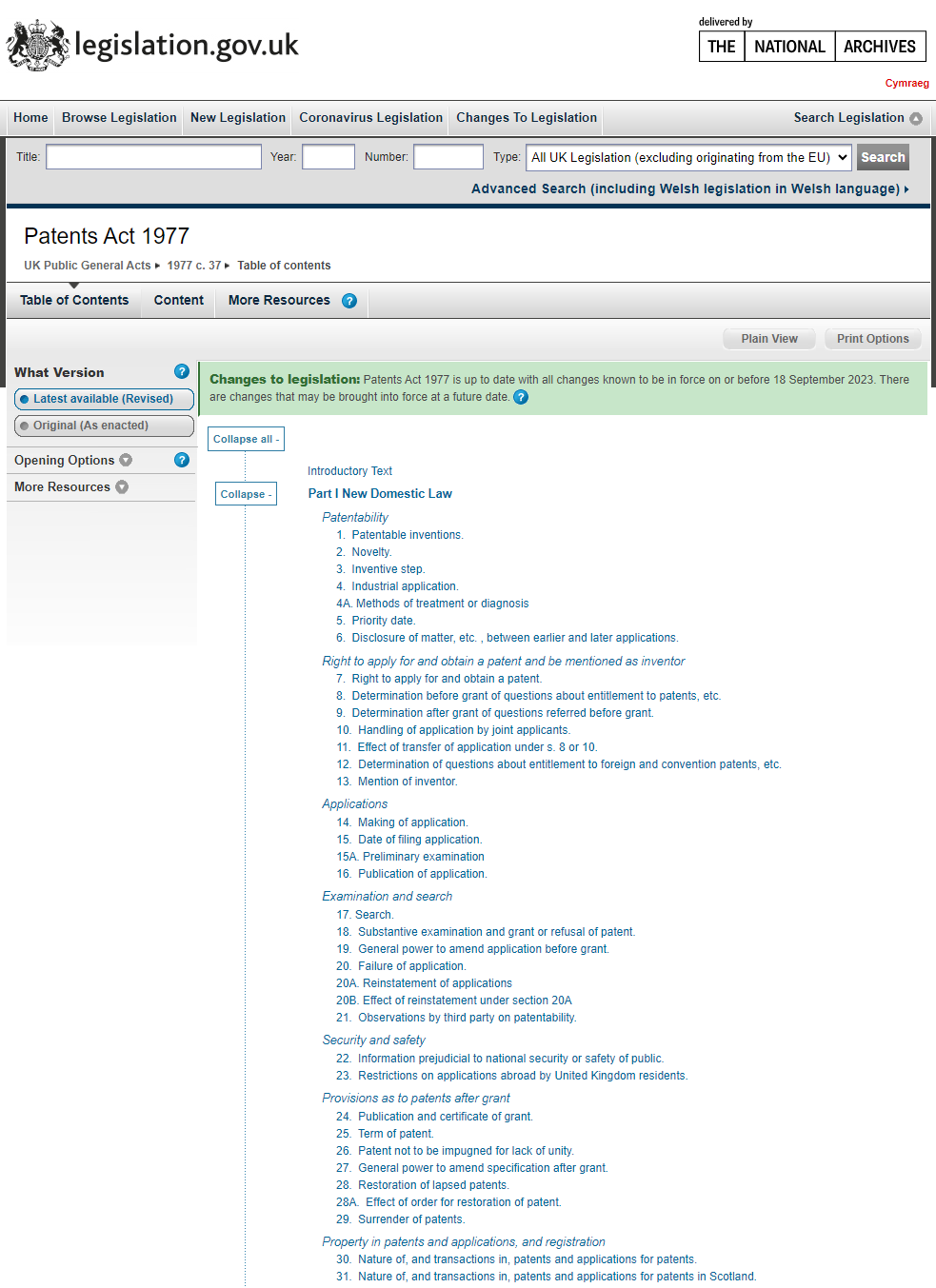
Many lawyers use this to view up-to-date legislation. What many don’t know though is it has a hidden XML data layer that provides all the information that is rendered within the website. This is a perfect machine-readable source.

Custom XML Parser
Even though we have a good source of machine-readable information, it doesn’t mean we have the information in a useful format for our RAG system.
Most current RAG systems expect “documents” to be provided as chunks of text (“strings” – very 1984). For legislation, the text of each section makes a good “document”. The problem is that the XML does not provide a clean portion of text as you see it on-screen:

Rather, the text is split up across different XML tags with useful accompanying metadata:

To convert the XML into a useful Python data structure, we need to build a custom XML parser. This turns the retrieved XML into text objects along with their metadata, making it easier to reference and cite the legislative sources. As with any markup processing, the excellent Beautiful Soup library is our friend. The final solution requires some recursive parsing of the structure. This always makes my head hurt and requires several attempts to get it working.
Langchain for Embeddings and RAG Architecture
This mini project provided a great excuse to check out the Langchain library in Python. I’d seen many use this on Twitter to quickly spin up proof-of-concept solutions around LLMs.
At first I was skeptical. The power of langchain is it does a lot with a few lines of code, but this also means you are putting yourself in the hands of the coding gods (or community). Sometimes the abstractions are counter-productive and dangerous. However, in this case I wanted to get something up-and-running quickly for evaluation so I was happy to talk on the risks.
This is pretty bleeding edge in technology terms. I found a couple of excellent blog posts detailing how you can build a RAG system with langchain. Both are only from late August 2023!
- https://betterprogramming.pub/harnessing-retrieval-augmented-generation-with-langchain-2eae65926e82
- https://deci.ai/blog/retrieval-augmented-generation-using-langchain/
The general outline of the system is as follows:
- Configure a local data store as a cache for your generated embeddings.
- Configure the model you want to use to generate the embeddings.
- OpenAI embeddings are good if you have the API setup and are okay with the few pence it costs to generate them. The benefit of OpenAI embeddings is you don’t need a GPU to run the embedding model (and so you can deploy into the cloud).
- HuggingFace embeddings that implement the sentence-transformer model are a free alternative that work just as well and are very quick on a GPU machine. They are a bit slow though for a CPU deployment.
- Configure an LLM that you want to use to answer a supplied query. I used the OpenAI Chat model with GPT3.5 for this project.
- Configure a vector store based on the embedding model and a set of “documents”. This also provides built-in similarity functions.
- And finally, configure a Retrieval Question-and-Answer model with the initialised LLM and the vector store.
You then simply provide the Retrieval Question-and-Answer model with a query string, wait a few seconds, then receive an answer from the LLM with a set of “documents” as sources.
Web Interface
Now you can run the RAG system as a purely command-line application. But that’s a bit boring.
Instead, I now like to build web-apps for my user interfaces. This means you can easily launch later on the Internet and also take advantage of a whole range of open-source web technologies.
Many Python projects start with Flask to power a web interface. However, Flask is not great for asynchronous websites with lots of user interaction. LLM based systems have the added problem of processing times in the seconds thanks to remote API calls (e.g., to OpenAI) and/or computationally intensive neural-network forward passes.
If you need a responsive website that can cope with long asynchronous calls, the best framework for me these days is React on the frontend and FastAPI on the backend. I hadn’t used React for a while so the project was a good excuse to refresh my skills. Being more of a backend person, I found having GPT-4 on call was very helpful. (But even the best “AI” struggles with the complexity of Javascript frontends!)


I also like to use Bootstrap as a base for styling. It enables you to create great-looking user interface components with little effort.

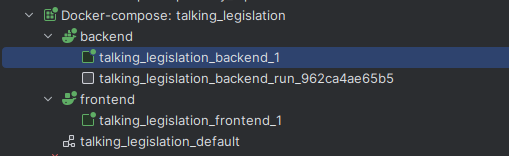
Docker
If you have a frontend and a backend (and possibly a task queue), you need to enter the realm of Docker and Docker Compose. This helps with managing what is in effect a whole network of interacting computers. It also means you can deploy easily.
WebSockets
I asked ChatGPT for some suggestions on how to manage slow backend processes:

I’d built systems with both async functionality and task queues, so thought I might experiment with WebSockets for this proof-of-concept. As ChatGPT says:

Or a case of building a TCP-like system on-top of HTTP to overcome the disadvantages of the stateless benefits of HTTP! (I’m still scared by CORBA – useful: never.)
Anyway, the WebSockets implementation was a pretty simple setup. The React front end App sets up a WebSocket connection when the user enters a query:

And this is received by an asynchronous backend endpoint within the FastAPI implementation:

Results and Observations
Here are some examples of running queries against the proof-of-concept system. I think it works really well – especially as I’m only running the “less able” GPT3.5 model. However, there are a few failure cases and these are interesting to review.
Infringement
Here’s a question on infringement. The vector search selects the right section of the legislation and GPT3.5 does a fair job of summarising the long detail.

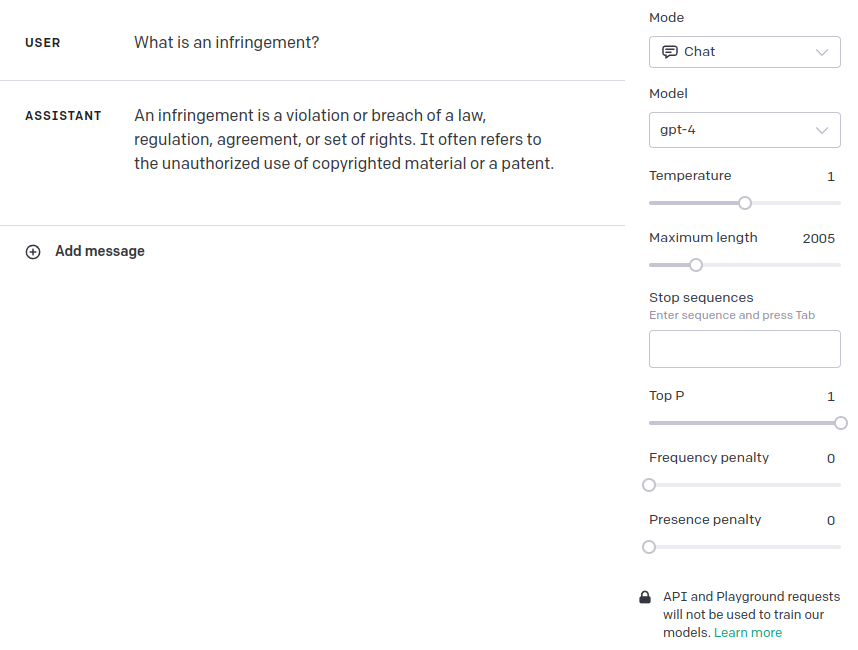
We can compare this with a vanilla query to GPT3.5-turbo:

And to a vanilla query using GPT4:
Inventors
Here’s an example question regarding the inventors:

Again, the vector search finds us the right section and GPT-3.5 summarises it well. You’ll see GPT3.5 also integrates pertinent details from several relevant sections. You can also click through on the cited section and be taken to the actual legislation.
Here’s vanilla GPT3.5:

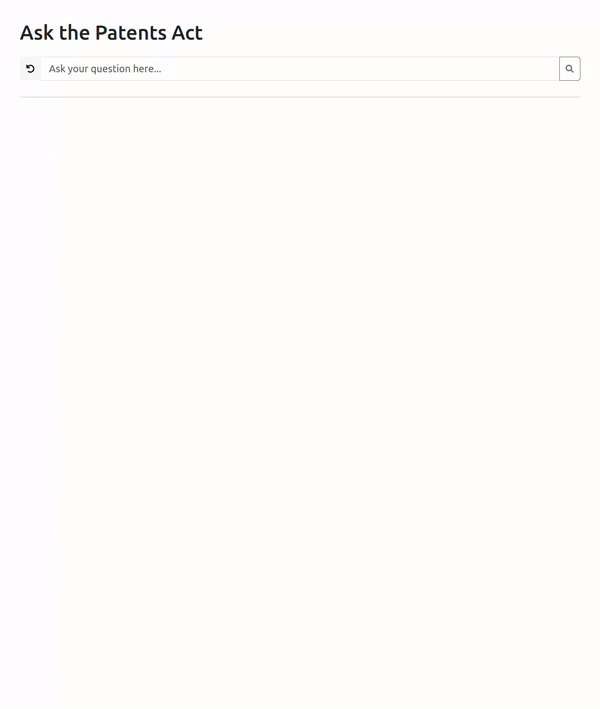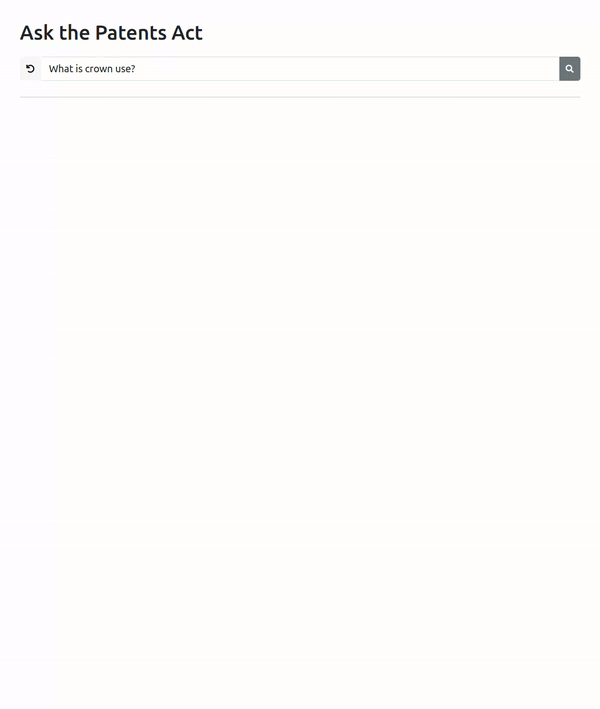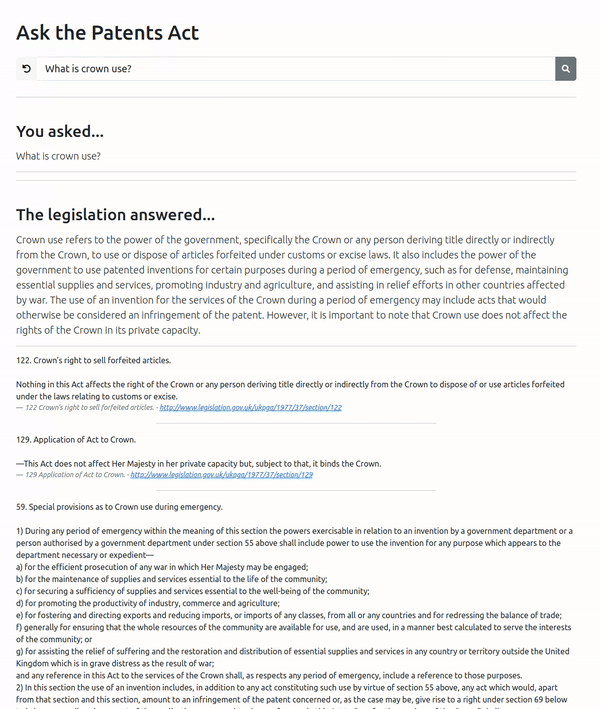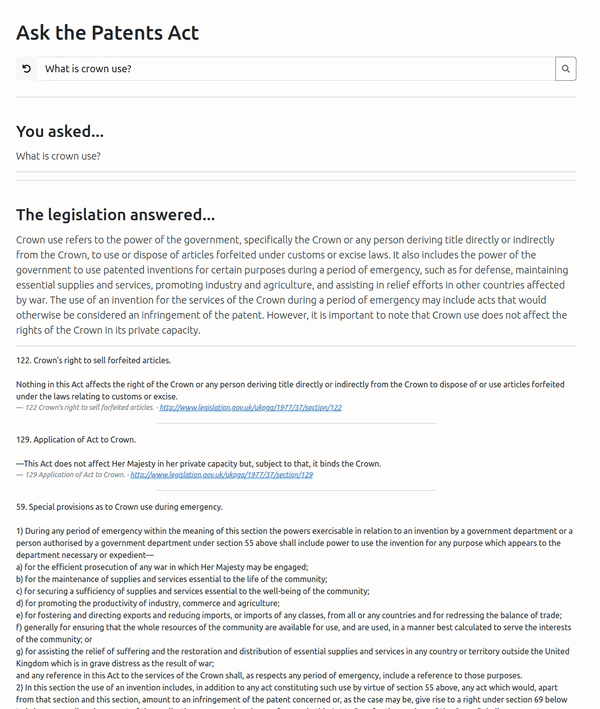
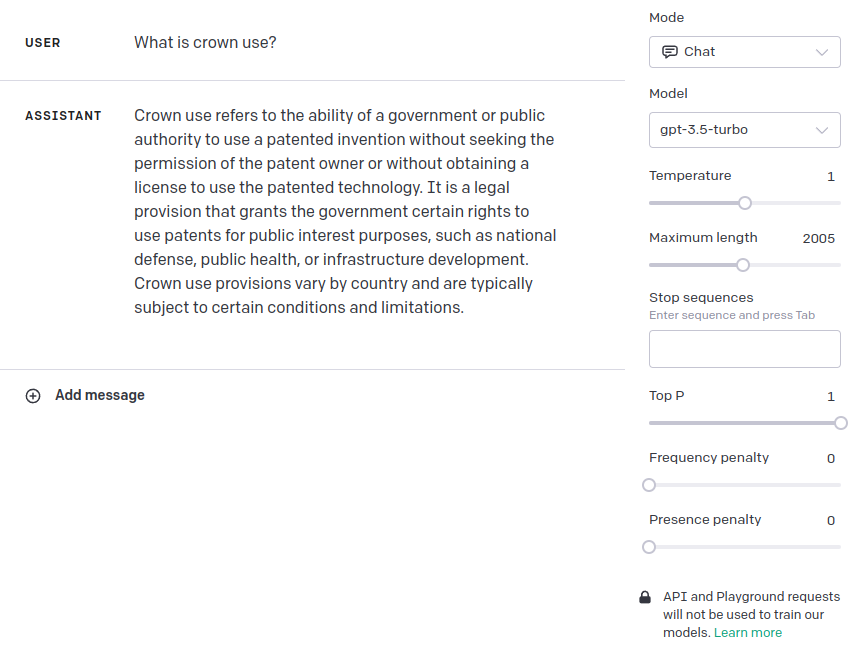
Failure Case – Crown Use
Here’s an interesting failure case – we ask a question about Crown Use. Here, the vector search is biased to returning a shorter section (122) relating to the sale of forfeited items. We find that section 55 that relates to Crown Use does not even feature in the top 4 returned sections (but would possibly be number 5 given that section 56 is the fourth entry).
Interestingly, this is a case where vanilla GPT3.5 actually performs better:
WebSocket Example
If you are interested in the dynamics of the WebSockets (I know all you lawyers are), here’s the console log as we create a websocket connection and fire off a query:

And here’s the backend log:

Future Work
There are a few avenues for future improvement:
- Experiment with the more expensive GPT4 model for question answering.
- Extend the number of returned sources.
- Add an intermediate review stage (possibly using the cheaper GPT3.5).
- Add some “agent-like” behaviour – e.g. before returning an answer, use an LLM to consider whether the question is well-formed or requires further information/content from the user.
- Add the Patent Rules in tandem.
- Use a conventional LLM query in parallel to steer output review (e.g., an ensemble approach would maybe resolve the “Crown Use” issue above).
- Add an HTML parser and implement on the European Patent Convention (EPC).
Summary
In summary, then:
Positives
- It seems to work really well!
- The proof-of-concept uses the “lesser” GPT3.5-turbo model but often has good results.
- The cited sources add a layer of trust and verifiability.
- Vector search is not perfect but is much, much better than conventional keyword search (I’m glad it’s *finally* becoming a thing).
- It’s cool being able to build systems like this for yourself – you get a glimpse of the future before it arrives. I’ve worked with information retrieval systems for decades and LLMs have definitely unlocked a whole cornucopia of useful solutions.
Negatives
- Despite citing sources, LLMs can still misinterpret them.
- The number of returned sources is a parameter that can significantly influence the system’s output.
- Current vector search algorithms tend to focus more on (fuzzy) keyword matching rather than the utility of the returned information, leaving room for further refinement.
Given I could create a capable system in a couple of days, I’m sure we’ll see this approach everywhere within a year or so. Just think what you could do with a team of engineers and developers!
(If anyone is interested in building out a system, please feel free to get in touch via LinkedIn, Twitter, or GitHub using the links above.)

2 thoughts on “Talking Legislation – Asking the Patents Act”