
I’ve been working for a while with Retrieval Augmented Generation (RAG) systems. This ranges from simple vectorisation of text to more complex libraries such as LangChain or LlamaIndex. This post explores some of the nuances of applying RAG to legal documents, with tips for powerful production systems.
I don’t particularly like the acronym “RAG”; I’m not keen on acronyms, jargon, or buzzwords. But I can’t control language, and I don’t have a better suggestion, so hey-ho.
Why RAG?
I am already seeing many people use large language models (LLMs) like ChatGPT to answer legal questions.
Normally the answers are wrong in some ways. Sometimes they are wrong in dangerous ways. However, the answers are not completely wrong; they are wrong in a “nearly there” or “halfway there” kind of way.
This matches what I have read in other fields and professions, such as medicine. The 80% of an answer is often there. 15% of the content is definitely wrong. 5% is dangerously wrong.
Often the low hanging fruit is found. But the law is applied in the wrong way based on the probabilities of Internet use, or important laws are missed.
RAG systems offer a way to improve the initial answers of LLMs by getting them to work with sources of information. We explored how this could work in this blog post. The present post develops that work with some more advanced techniques.
Naive Chunking
The main problem with naive RAG implementations is that it is independent of document structure. Early transformer architectures like BERT were limited to around 512 tokens, meaning documents were “chunked” in batches of around 400 words or less (a token is a word or word part). Normally, text was extracted naively – just dumping any string content from larger structures into a single string, then chunking that single string based on token counts. In practice this makes for poor retrieval, as semantically continuous sections are broken apart mid-section & with disregard for meaning.
Document as a Tree
Now, a more sophisticated view of a document is as a tree structure. A tree is a particular instance of a graph. The tree has parent and child nodes, separated by edges. There are well known methods for building and navigating trees.
Now most electronic documents are in a tree form already. The webpage you are reading this on is a tree in the form of a complex Document Object Model (DOM). XML and JSON data structures are often parsed into nested dictionaries that can be represented as trees. Word documents are stored as XML under the hood. PDFs – well…

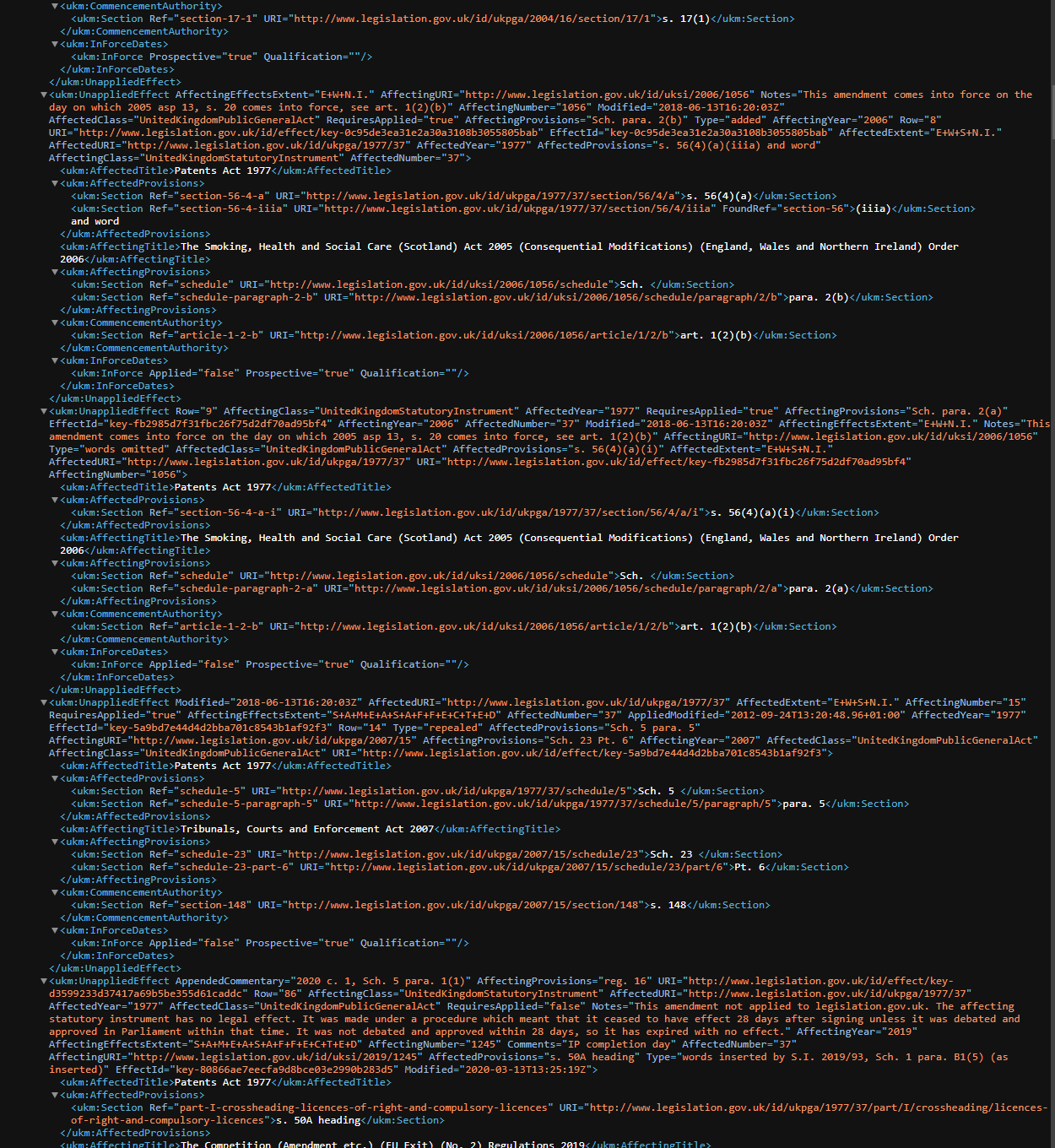
However, most electronic documents are designed for machines to parse and extract data not semantic meaning. For example, often they are arranged like (and built from) complex databases. Only a subset of information is semantically useful to human beings, which is why we need to render things as pretty webpages that hide much of the complexity.
RAG is concerned with the semantic content of documents rather than the syntactic contents. In fact, sticking XML or JSON into a RAG system as text tends to throw it off, as matches concentrate in similarities with the encoded syntax rather than the encoded semantic content. RAG encoders just need the semantic content in a manner similar to a human viewer. Also, the raw electronic data structure, when represented as a string, is very verbose, so it costs a lot in time and resources to encode.
Legal Documents
Legal documents are often long and complex. That’s why people pay lawyers a lot of money. But lawyers are still human, and humans can’t make sense of large streams of dense text (at least without an entertaining narrative or decent characterisation). Hence, lawyers use a variety of tools to help humans parse the documents. These include “sections” (with an arbitrary level of nesting) and “tables of contents”. These are all forms of tree structure. Normally, we represent them linearly with indents to represent levels in the tree hierarchy.



But we can also visualise the same data structure as more of a tree-like shape:
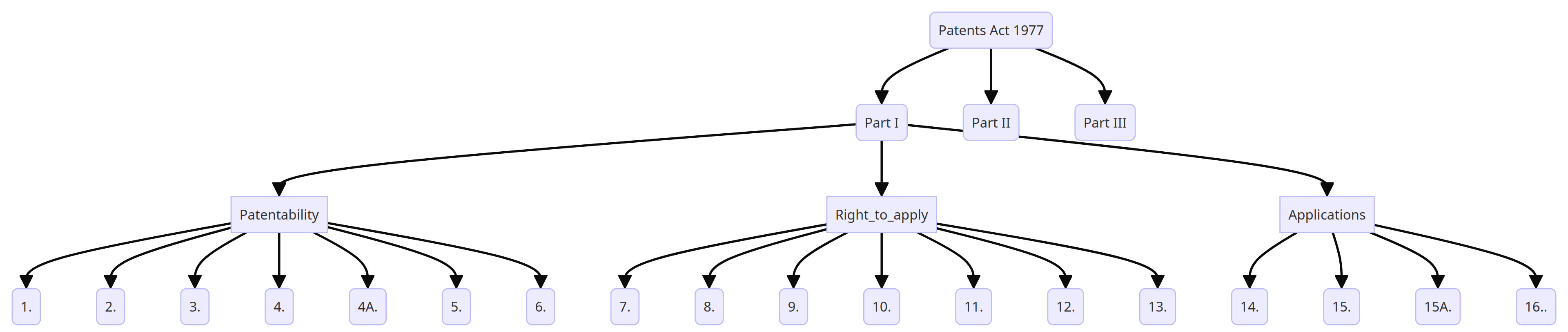
As humans, we know how to use these tree structures to quickly arrive at the section we need, by iterating over the tree. Often we approximate something similar to a breadth-first search – we look at the first level of topics, determine if one of them is relevant to our query, then look at the next set of titles within the relevant topic, repeating until we arrive at a relevant portion of text.
The tree structure of legal documents is also used when citing sources. In legal argument, we cite either the absolute reference assigned to the leaf nodes (e.g., “Section 4, Patents Act 1977”) or the trail down the tree (“Guidelines for Examination, A-II-1.2.1”).
In a particular area of law, like patent law, we often have a small number of “documents” but a large number of text chunks. In the area of case law, we have a large number of documents, each with around 100-200 paragraphs, often split via headings or subheadings. In the area of patent law, we have a very large number of patent publications (250 million odd), each with between 20 and 500+ paragraphs, split roughly into a number of canonical headings, some with subsections and most semantically chunked by embodiment.

RAG on Trees
Based on the above we have an intuition that using the tree structure of legal documents can provide for more meaningful vector search and source citation. How might we begin to build a useful search system?
Now LlamaIndex does have a tree index but this seems separate from their vector index. We really want to combine the power of freeform vector search, with the guidance of the tree structure for relevance and easy citation.
1. Parsing the Document
This is often a challenge in itself. Each document type needs a bespoke solution. Let’s take the EPO Guidelines for Examination as an example. We have the option of a PDF download or a series of web-pages.
a) PDF
Off-the-shelf PDF parsers are poor at extracting the tree structure – you get text chunks that split up some semantic sections or merge other sections.

b) Web pages
Most web-page versions of materials tend to be located across a series of web-pages, with one web-page per leaf node of the tree. However, because this is 2024, the actual HTML for the webpage is a mess of Javascript and other front-end rendering functions, leaving us scratching our heads as to where the data is actually located.





2. Building the Tree
If we write our own scripts per document source to handle data ingress (e.g., based on a PDF file path or a web URL), our next challenge is to parse the initial data structure into a useful semantic tree.
This often requires simplifying and validating the data structure we start with, placing everything into a common tree model.
LlamaIndex does have the data abstractions of Documents and Nodes. This is a good start. Documents here would be the high level data source (e.g., Guidelines for Examination, Case Law Book, Statute, Rules etc.) and the Nodes would represent the different levels of the tree. We thus would need to work out how the levels of the tree are represented in the initially received data structure representing the parsed data source and convert that into Nodes and their relationships.
With a tree, the relationships are the relatively straightforward parent-child relationship. The tree is represented as a Directed Acyclic Graph (DAG – no relation), where the direction normally indicates parent to child (as per the graphs above). LlamaIndex has a relationships property built into the Node data model so we could use that. Or we could build our own simple model.
To leverage the good work of the LlamaIndex team and speed up development, we might create the Documents and Nodes ourselves, but then use the inbuilt vectorisation of those nodes. We can then build custom retrieval pipelines. However, there is merit to building our own version, in that it is typically easier to see what is going on and we are not beholden to a fast-moving library.
My experience has been that plain old cosine similarity via the dot product works pretty much near identically to more complex methods, and using OpenAI’s API or SentenceTransformer for embeddings also has similar performance. What makes a big difference to performance is the logic of retrieval and how the prompts are generated, typically in an iterative manner.
In terms of the text data stored with each node in the tree, we can start with the text of the titles as presented.
3. Querying
If we have a tree data structure representing our legal document, with the tree representing the semantic sections of the document we can begin to have some fun with query strategies.
Unfortunately, it’s all a bit “wild west” at the moment in terms of querying strategies and algorithms. There are a lot of academic papers with some useful ideas and custom solutions but none of these are ready for a production implementation or have a stable library you can drop in. They will come in time, but I’m impatient!
a) Naive Start
A naive starting point is to flatten the tree and to perform a vector search over all the nodes. This would give us results that mix different layers of the tree.
One problem with this is that titles are short and they often do not contain all the information that is needed to determine whether the nodes below are relevant. This leads to noisy results at best and just noise at worst.
b) Breadth-First Vector Search
The next natural step is to combine a normal breadth-first search with the vector search. This would involve filtering nodes by level, performing a vector search on the filtered nodes, and then picking a level to explore based on those results.
This again would suffer from the problem of the un-informative title text as discussed above.
c) Breadth-First Vector Search with Summary Embedding
One suggestion to address uninformative parent node text is to build a summary for every parent node, based on the contents of the child nodes. This can be built iteratively from the leaf nodes up.
For example, we iterate over the leaf nodes, get a lowest level set of parent nodes, iterate over those parent nodes and use a cheap LLM (like GPT3.5-turbo or a local 7B model) to summarise the text in text form at each parent. We then repeat starting with those parent nodes, until we have processed the whole tree. A human-readable text summary could be encoded with the title to get the embedding and/or may be read by a human being.
A variation on the above that uses the same algorithm generates an embedding for a parent node based on the concatenated text content of the children nodes. This can then be searched in the breadth-first manner above and should be more relevant and accurate.
The summary encoding discussed here would only need to be run once after the tree has been built.
d) Breadth-First Vector Search with Query-Summary Embedding
A further possibility to increase the accuracy of the method above, is to create custom summaries for each query. This custom summary may be used together with, or instead of, the generic summary above. This is based on the intuition that in a large section only some bits may be relevant, so a generic summary might not capture all the ways the section is relevant.
One problem with this approach is it would be more expensive. However, as cheaper or local models tend to be good at summarising, and embeddings cost peanuts, the cost may not be prohibitive (e.g., 1-50p per query via an API or free but slower if we use local models).
This approach would implement a Heath-Robinson (Rube-Goldberg for our US cousins) version of attention, but in a manner that may be more “explainable”. A user is provided with feedback in the form of the custom summary that represents what portions are deemed relevant to place in the summary.
The custom summary may also be used in the actual generation prompt. Normally, RAG systems dump the text of the most relevant nodes in a prompt together with a question to get an answer. Custom summaries of sections prior to specific text from the section might improve question-answering by setting up the context for the probabilistic retrieval.
e) Chain-of-thought or Iterative Querying
Another approach that could be used modularly with the above approaches is an iterative refinement of the nodes.
For example, if we perform a breadth-first search and select a particular section based on a generic and/or custom summary, we could combine the child node text (with a view on LLM context limits) and apply some kind of scoring based on whether the LLM thought the combined text was relevant. Now my experience is that LLMs aren’t very good at consistent scoring, especially over successive requests, but the higher power models are not too bad at ranking sections in order of relevance or determining reasons why a bit of text may or may not be relevant. This could then be built into a scoring system for selection of relevant portions of text or lower nodes. However, it does get expensive quickly.
4. Linking Between Trees
With the example of the EPO Guidelines above, we also see the possibility of linking between trees. Some of these links we might be able to parse from the extracted data. For example, we might be able to extract the links to associated articles and rules as the hyperlinks are within the <div> with the text that forms the link node.
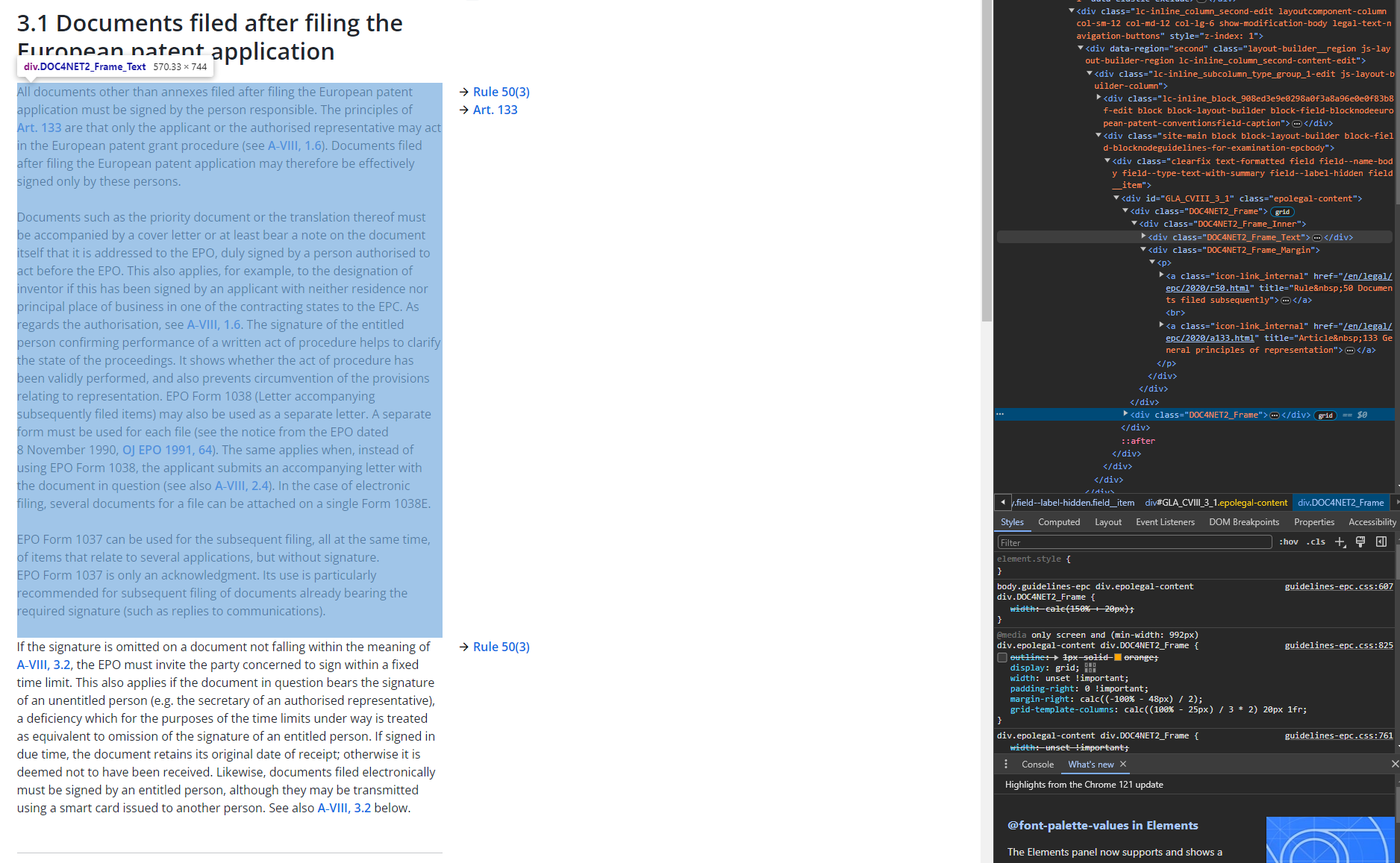

We would need to store some metadata with each node representing a parsed form of the article or rule (e.g., maybe a flattened list of the string portions of a particular article or rule node and an integer version of the main part and/or subsequent part).
In PDFs and other unstructured text, we can maybe setup a “simple” regex rule to detect citations of articles and rules:

Another possibility is to also extract cases cited by each node, storing the case as string, number, and hyperlink.
The Manual of Patent Practice has links to sections, cases, and paragraphs of cases within the text. These could be parsed by regex, HTML parsing, and/or LLM to generate metadata on links.

Vector Section with Legal Filtering
Once extracted, links between portions of statute, cases, and guidance could be used in the retrieval logic prior to prompt generation.
For example, a flattened search over all nodes in a set of guidance could be used to extract the linked articles across the top N results. This could then be combined with a further flattened search over the articles themselves. The articles could then be scored based on both searches. Top scoring articles could then be used to refine vector search results and/or included in an question-answering prompt.
Improving Access to the Law
In my experience with tests, the strength of vector search is its ability to brainlessly search without any pre-thought. The user does not need to work out what key words need to be typed, they can just dump a text description of their problem, poor spelling and all. This has huge power for increasing access to the law.
However, vector search is noisy, has weird quirks and biases, and out-of-the-box RAG is not “safe” enough to provide any coherent legal advice. But improvement seems to be within the realm of possibility. With some work.
I tried a few examples on D1 EQE exam questions. GPT4, the best performing model provides a half-correct answer (a score of 30-40% or 0% depending on how harsh the Examiner was feeling).
Here is an example of asking GPT4 what articles of the EPC might be relevant to answer a D1 question:

Unfortunately, GPT4 missed the main bit of the answer, which involved Article 123(2) EPC (added subject matter), as this required some next-level working from the initial facts.
When using a naive RAG implementation, I got an improved answer that did highlight the applicability of Article 123(2) EPC. The top 10 retrieved portions of the Guidelines and Case Law were vaguely relevant, but they needed more work on filtering. The poor PDF and web-page parsing did not help.

This offers a possibility that with a bit of tweaking and building, we could up our 0-40% GPT4 result to a scrapped pass of 51%. If GPT4 can pass the EQE, what does that mean for legal knowledge?
(In my mind possibly good things for industry and the public, possibly painful change for the patent profession.)
Future Work
The systems are not there yet. The out-of-the-box-in-a-hackathon-afternoon solutions are not good enough as of February 2024. But progress seems possible. We haven’t hit a technology “wall” yet with integrating the power of LLMs.
The changes will likely be as big as the Internet.
This is how I accessed the law when I started in the patent profession:


This is how we currently access the EPO Guidelines:


UK patent case law:
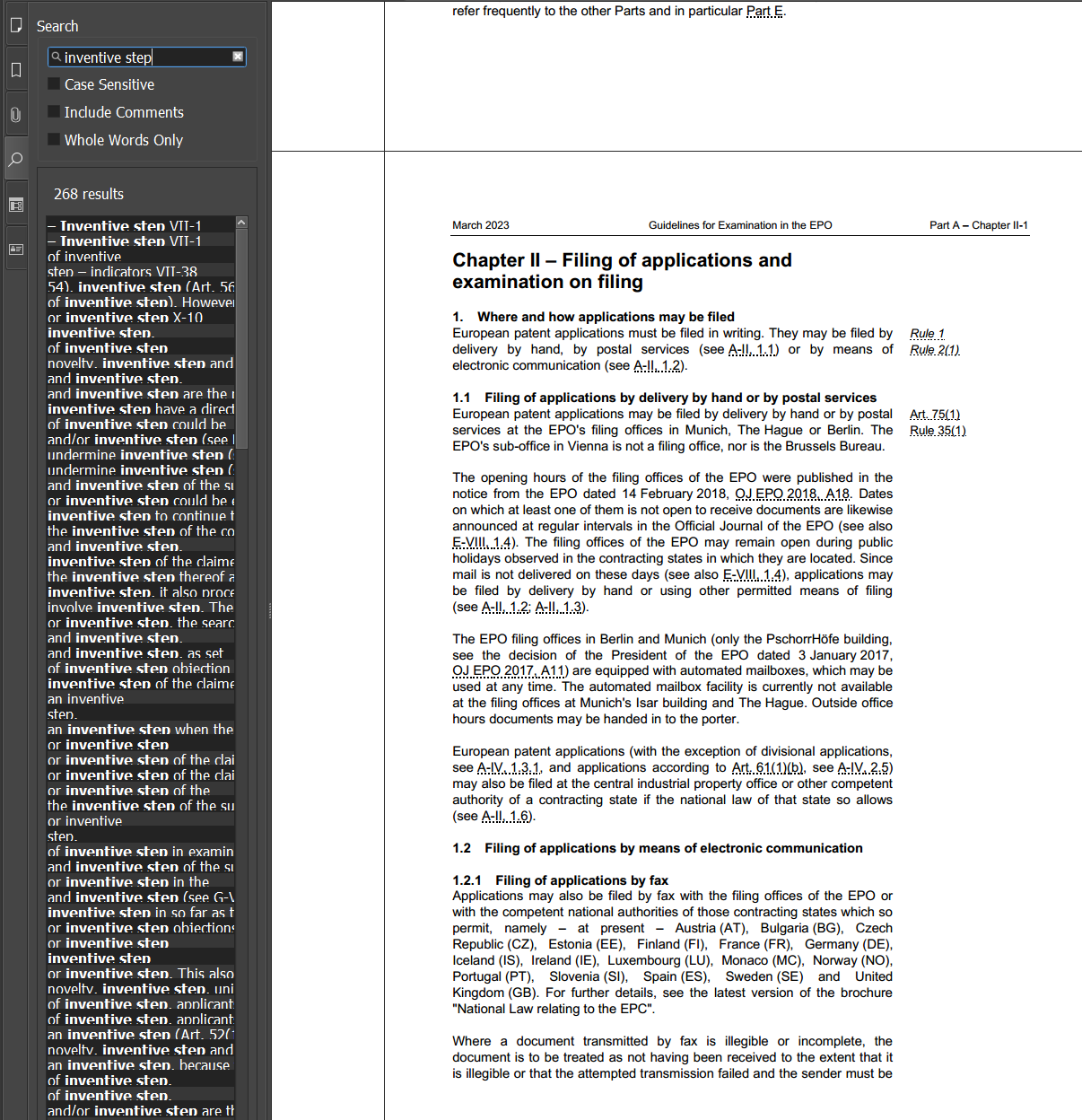
And UK patent legislation:

Even an implementation of the out-of-the-box approaches would be a big improvement over this.
But we haven’t yet really touched the possibilities of augmented law, when we start building systems that “reason” and process over large bodies of text. Exciting times!

One thought on “RAG for Legal Documents”