
This article will look into how the process of obtaining a patent could be automated using deep learning approaches. A possible pipeline for processing a patent application will be discussed. It will be shown how current state of the art natural language processing techniques could be applied.
Brief Overview of Patent Prosecution
First, let’s briefly look at how a patent is obtained. A patent application is filed. The patent application includes a detailed description of the invention, a set of figures, and a set of patent claims. The patent claims define the proposed legal scope of protection. A patent application is searched and examined by a patent office. Relevant documents are located and cited against the patent application. If an applicant can show that their claimed invention is different from each citation, and that any differences are also not obvious over the group of citations, then they can obtain a granted patent. Often, patent claims will be amended by adding extra features to clearly show a difference over the citations.
Patent Data
For a deep learning practitioner the first question is always: what data do I have? If you are lucky enough to have labelled datasets then you can look at applying supervised learning approaches.
It turns out that the large public database of patent publications is such a dataset. All patent applications needs to be published to continue to grant. This will be seen as a serendipitous gift for future generations.
Search Process
In particular, a patent search report can be thought of as the following processes:

A patent searched locates a set of citations based on the language of a particular claim.
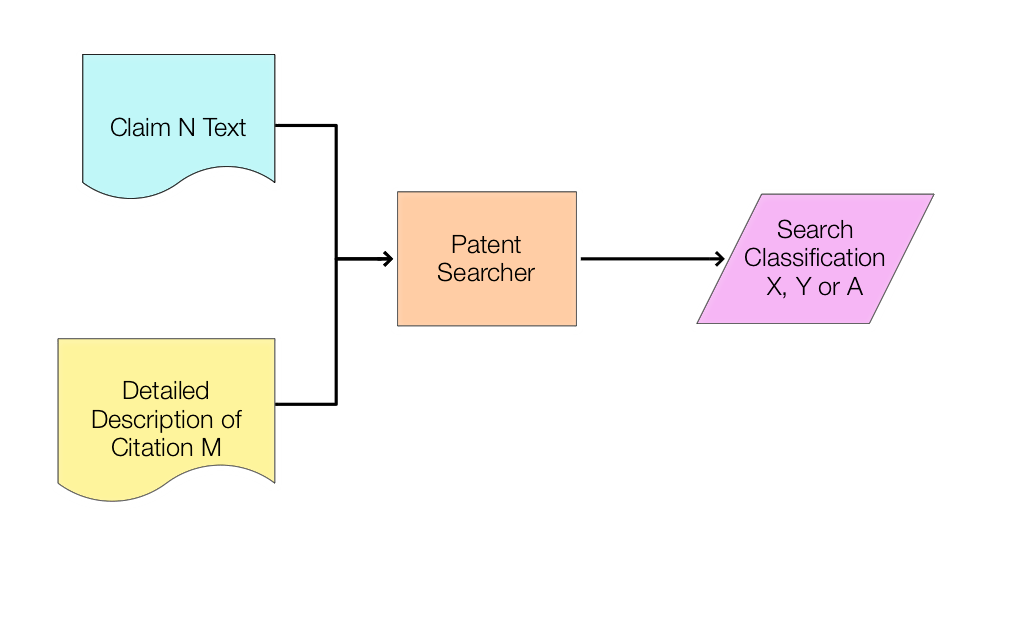
Each located citation is labelled as being in one of three categories:
– X: relevant to the novelty of the patent claim.
– Y: relevant to the inventive step of the patent claim. (This typically means the citation is relevant in combination with another Y citation.)
– A: relevant to the background of the patent claim. (These documents are typically not cited in an examination report.)
In reality, these two processes often occur together. For our ends, we may wish to add a further category: N – not cited.
Problem Definition
Thinking as a data scientist, we have the following data records:
(Claim text, citation detailed description text, search classification)
This data may be retrieved (for free) from public patent databases. This may need some intelligent data wrangling. The first process may be subsumed into the second process by adding the “not cited” category. If we move to a slightly more mathematical notation, we have as data:
(c, d, s)
Where c and d are based on a (long) string of text and s is a label with 4 possible values. We then want to construct a model for:
P(s | c, d)
I.e. a probability model for the search classifications given the claim text and citation detailed description. If we have this we can do many cool things. For example, for a set c, we can iterate over a set of d and select the documents with the highest X and Y probabilities.
Representations for c and d
Machine learning algorithms operate on real-valued tensors (n*m -dimensional arrays). more than that, the framework for many discriminative models maps data in the form of a large tensor X to a set of labels in the form of a tensor Y. For example, each row in X and Y may relate to a different data sample. The question then becomes how do we map (c, d, s) to (X, Y)?
Mapping s to Y is relatively easy. Each row of Y may be an integer value corresponding to one of the four labels (e.g. 0 to 3). In some cases, each row may need to represent the integer label as a “one hot” encoding, e.g. a value of [2] > [0, 0, 1, 0].
Mapping c and d to X is harder. There are two sub-problems: 1) how do we combine c and d? and 2) how do we represent each of c and d as sets of real numbers?
There is an emerging consensus on sub-problem 2). A great explanation may be found in Matthew Honnibal’s post Embed, Encode, Attend, Predict. Briefly summarised, we embed words from the text using a word embedding (e.g. based on Word2Vec or GloVe). This outputs a sequence of real-valued float vectors for each word (e.g. vectors of length ~300). We then encode this sequence of vector into a document matrix, e.g. where each row of the matrix represents a sentence encoding. One common way to do this is to apply a bidirectional recurrent neural network (RNN – such as an LSTM or GRU), where outputs of a forward and backward network are concatenated. An attention mechanism is then applied to reduce the matrix to a vector. The vector then represents the document.
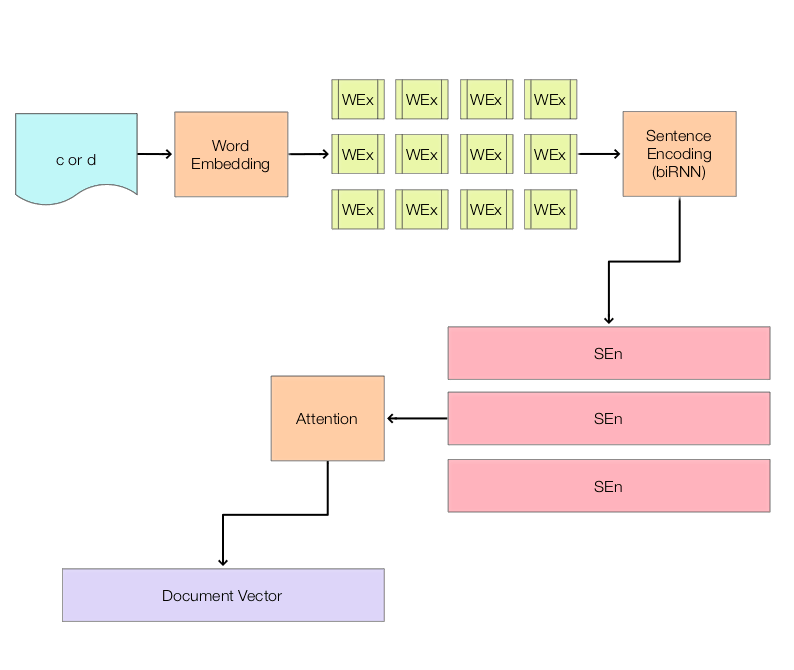
A simple way to address sub-problem 1) is to simply concatenate c and d (in a similar manner to the forward and backward passes of the RNN). A more advanced approach might use c as an input to the attention mechanism for the generation of the document vector for d.
Obtain the Data
To get our initial data records – (Claim text, citation detailed description text, search classification) – we have several options. For a list of patent publications, we can obtain details of citation numbers and search classifications using the European Patent Office’s Open Patent Services RESTful API. We can also obtain a claim 1 for each publication. We can then use the citation numbers to look up the detailed descriptions, either using another call to the OPS API or using the USPTO bulk downloads.
I haven’t looked in detail at the USPTO examination datasets but the information may be available there as well. I know that the citations are listed in the XML for a US grant (but without the search classifications). Most International (PCT / WO) publications include the search report, so as a push you could OCR and regex the search report text to extract a (claim number, citation number, search category) tuple.
Training
Once you have a dataset consisting of X and Y from c, d, s, the process then just becomes designing, training and evaluating different deep learning architectures. You can start with a simple feed forward network and work up in complexity.
I cannot guarantee your results will be great or useful, but hey if you don’t try you will never know!
What are you waiting for?
