On 22 February 2019, a Board of Appeal of the European Patent Office referred a set of questions relating to computer simulations to the Enlarged Board of Appeal (the European patent version of the Supreme Court). This is being considered as pending referral G1/19. This is only the second time that the Enlarged Board of Appeal have considered questions relating to computer-related inventions. If the Enlarged Board of Appeal choose to answer the questions, the result could influence how machine learning and artificial intelligence inventions are examined in Europe.
The full interlocutory decision that led to the referral can be found here: G1/19.
The original case on appeal related to modelling pedestrian crowd movement. Claim 1 of the main request considered a model of a pedestrian that included a “provisional path” and “an inconvenience function”, where movement was analysed around various obstacles. The models could be used to design buildings such as train stations or stadiums.
The Board of Appeal found that claim 1 avoided the exclusions of Articles 52(2) and (3) EPC as it related to a “computer-implemented method”. However, the Board considered that claim 1 was straightforward to implement on a computer “requiring only basic knowledge of data structures and algorithms”. The Board also deemed that the design of the method was not motivated by technical considerations concerning the internal functioning of the computer. The question of inventive step thus revolved around whether claim 1 provided further technical aspects that go beyond the mere functioning of a conventionally programmed computer.
Electrons are People too?
The Appellant argued that the claim provided a further technical effect in the form of “a more accurate simulation of crowd movement”. The Appellant argued that modelling a crowd was no different from modelling a set of electrons. The case on appeal thus considered what form of activities could be seen as a technical task producing a technical effect. The Board was not convinced that numerically calculating the trajectory of an object as determined by the laws of physics was always a technical task; for example, they believed that a technical effect requires, at a minimum a direct link with physical reality, such as a change in or a measurement of a physical entity.
*Divergence Klaxon*
The problem for the Board of Appeal was that the Appellant cited T 1227/05, which is discussed here. In this case, a numerical simulation of a noise-affected circuit was deemed to provide a technical effect as it related to “an adequately defined class of technical items”. However, the Board agreed that the arguments applied in T 1227/05 could be applied to the modelling of pedestrians, as the laws of physics apply to both people and electrons. The Board appeared minded to go against T 1227/05, on the grounds that the benefits were either in the brains of the engineers using the simulations or were the common benefits of using computers to implement testing methods.
Is Software 2.0 Patentable in Europe?
The Board appreciated that numerical development tools and computer simulations play an important role in the development of new products. Many of the points under discussion could also apply to the much larger field of machine learning, where the lines between measurement and simulation are often blurred. Indeed, the Board note this saying that there may be no ground to distinguish between simulating and using a model to predict the function of a system. The Board believed that a decision on the patentability of simulation methods needs to be made, and guidance on the interpretation of Articles 52(2) and (3) and 56 EPC would be useful.
We have Questions
The Board have thus referred three questions to the Enlarged Board of Appeal:
In
the assessment of inventive step, can the computer-implemented simulation of a
technical system or process solve a technical problem by producing a technical
effect which goes beyond the simulation’s implementation on a computer, if the computer-implemented
simulation is claimed as such?
If
the answer to the first question is yes, what are the relevant criteria for
assessing whether a computer-implemented simulation claimed as such solves a
technical problem? In particular, is it a sufficient condition that the
simulation is based, at least in part, on technical principles underlying the
simulated system or process?
What
are the answers to the first and second questions if the computer-implemented
simulation is claimed as part of a design process, in particular for verifying
a design?
The referral raises a number of interesting points for computer-related inventions. In the interlocutory decision the Board go back to VICOM (T 208/84) to argue that a direct link with physical reality seems necessary. However, they cited different cases to suggest that it was not clear whether a direct or “real-world” effect needed to be present to provide a technical effect. With simulations there is also a question of whether non-claimed features, such as a future use, could be taken into account when assessing inventive step.
The Board of Appeal have done well to summarise the issues in the area of simulation and to highlight where further clarification would be useful. As is often the case, the actual claimed invention appears to be a straw person for consideration of broader policy questions.
The referral is timely. Cases relating to machine learning and “artificial intelligence” are increasing rapidly. Last time the Enlarged Board of Appeal had a chance to clarify the law for computer-implemented inventions, in G3/08, they dodged the bullet, arguing that the referral was inadmissible. The well-formed points by the Board of Appeal, and the general zeitgeist, mean that they may not be able to do this again.
Examination practice at the European Patent Office follows a set of Guidelines. These are published online and provide guidance for European Examiners and applicants. They are updated annually.
An updated set of Guidelines came into force on 1st November 2018. The recent updates introduce major amendments to sections that cover subject matter that is excluded from patentability in European. These sections include those directed to “mathematical methods”, “schemes, rules and methods for performing mental acts, playing games or doing business” (often shortened to “business methods”), and “programs for computers”. The updates are relevant to those filing applications related to “computer-implemented inventions” (often colloquially referred to as “software patents”).
Although the amendments do not significantly change current practice at the European Patent Office, they do expand the guidance on what may and may not be protected with a European patent. They represent a significant upgrade and demonstrate the maturity of the case law with regard to computer-implemented inventions.
This post will review and highlight the updates. The post may be useful for those seeking to patent machine learning and artificial intelligence inventions. The updates cover the following areas:
claims to distributed computing systems;
inventions that use mathematical methods;
AI and machine learning inventions;
inventions that cover simulations and models; and
inventions that relate to business methods, gaming, mental acts or computer programs.
Distributed Computing
Section F-IV, 3.9.3 has been added to the section relating to claims for computer-implemented inventions. It provides expanded guidance and an example relevant to processes operating in a distributed computing environment. These processes form a basis for many real-world implementations of computer-implemented inventions. For example, a smartphone accessing a cloud computing service would implement a process operating in a distributed computing environment.
The section sets out the current practice of the European Patent Office. Claims in a claim set may be directed to each entity of the distributed system and/or the system as a whole. Such a claim set may be argued to meet the requirement for multiple independent claims set by Rule 43(2)(a) EPC, i.e. the claims may be allowed despite having multiple independent claims in the same category because the subject-matter of the claims relates to a plurality of interrelated products. However, each individual claim will need to meet the requirements of novelty, inventive step and clarity.
For example, if a cloud computing service provides a new image classification function via an application programming interface that is accessed by a smartphone, a claim set may feature apparatus claims to both a server computing device (the cloud server) and a mobile computing device (the “accessing device” or smartphone). If the smartphone is simply a generic smartphone making a network request (e.g. an “HTTPS request to a REST API endpoint”), it will likely not be new when compared to known smartphones. An objection will be raised against the smartphone claim. However, if the smartphone implements some new low-level processing, e.g. some new feature extraction process that is specific to the new image classification function (like pre-extracting cat-like facial features), it may also be new and inventive in itself and be allowed.
The updated section draws our attention to the need for clarity in claims to distributed entities. It recommends that distributed method claims specify the entity that is performing each method step.
Claiming distributed processes in a challenge. In practice, one entity often implements most of the new and inventive process (e.g. the cloud server), while other devices are relatively “thin” and generic (e.g. the smartphone). However, claims to the accessing device are often of greater commercial value (e.g. they might allow a royalty for each smartphone that is sold). This often leads to the inclusion of claims to the mobile computing device in a claim set, but a high likelihood of an objection being raised by the European Examiner.
To attempt to overcome novelty and inventive step objections to “accessing device” claims, it is common to include an indirect or implicit reference to the functions of the server computing device. This can then lead to one or more clarity, novelty or inventive step objections. For example, the indirect features may trigger a clarity objection for not clearly specifying features of the “accessing device”. Alternatively, the indirect features may be ignored for novelty and/or inventive step, as they are deemed to present no inherent structural limitations for the “accessing device”.
When drafting claims to distributed systems, it is worth questioning the inventors to determine what functions may be implemented with low-level adaptations to the accessing device. If the invention can be embodied in an “app”, it is worth looking at the architecture of the app, and the sequence of low-level system calls it may be implementing. This may not be obvious to the inventors, as commercial and engineering demands often require as much functionality as possible to be embodied on the back-end in the cloud.
Mathematical Methods
The section on the examination of mathematical methods has been re-written and two sub-sections have been added. A first sub-section – 3.3.1 – now provides specific guidance for artificial intelligence and machine learning. A second sub-section – 3.3.2 – expands upon claims to simulation, design or modelling.
The updated guidance is now clearer on the importance of “technical means”, i.e. a concrete implementation in a field of technology, when an invention makes use of mathematical methods. This complements the recent changes to practice for “abstract inventions” in the United States.
I really like the updates to this section and the inclusion of helpful concrete examples. The section emphasises that a mathematical method or algorithm per se will not be enough to make a claim feature patentable, although many patentable inventions do have a mathematical or algorithmic basis.
Examples of the Fast Fourier Transform, geometric objects and graphs are provided: these features may contribute to the technical character of an invention if they contribute to producing a technical effect that serves a technical purpose. Put another way, these features need to be provided in a context that relates to an engineering problem encountered in the real-world, and the use of these features needs to result in a change in the real-world that helps solve that problem. This is further emphasised later in the guidance – the technical purpose of the mathematical features needs to be specific rather than generic, and the claim needs to be functionally limited to the technical purpose, either explicitly or implicitly.
What kind of applications are seen by the European Patent Office to be “technical”? My personal definition is: does the application relate to something in the real-world that requires knowledge that is taught in an undergraduate engineering degree? If the answer is “yes”, then the application is “technical”. If the answer is “no”, then the application may not be “technical”.
Section 3.3 now provides a useful list of purposes that are deemed “technical”. These include:
controlling a specific machine or technical process, e.g. an X-ray apparatus or steel cooling;
using measurements to control a machine or technical process, e.g. using a compaction machine to achieve a desired material density;
digital audio/visual processing, this can be relatively high-level – detecting people is a provided example (but a clear relation to captured data is recommended);
processing speech data, e.g. to generate text (but processing text per se may not be technical);
encoding data, e.g. for transmission or storage;
cryptography;
load balancing;
generating higher-level measurements by processing data from physiological sensors or other medical diagnosis;
analysing DNA samples to provide a genotype estimate; and
simulating “technical” things (this is described in more detail in new sub-section 3.3.2).
The section stresses that there must be a sufficient link between the technical purpose of the invention and the mathematical method steps, for example, by specifying how the input and the output of the sequence of mathematical steps relate to the technical purpose so that the mathematical method is causally linked to a technical effect. When drafting an application for Europe for an invention that features mathematical operations (e.g. equations and/or algorithmic designs), it is recommended to place such an explanation in the description – this can then be pointed to in examination if any objection is raised.
Similar to practice in the United Kingdom, the section ends by indicating that a feature may contribute to the technical character of an invention independently of any technical application, when the claim is directed to a specific technical implementation of a mathematical method, and the mathematical method is particularly adapted for that implementation in that its design is motivated by technical considerations of the internal functioning of the computer. Using the Fast Fourier Transform example, it may be possible to obtain protection for a new digital implementation of the Fast Fourier Transform, if you were performing specific mathematical operations that were adapted to the available computing resources of the implementation, e.g. available memory registers, processing cores, etc.
When considering inventions involving mathematical methods, one useful approach is to make an initial determination:
Does the invention relate to a specific engineering application (e.g. what branch of “applied” maths is being considered)?
Or does the invention relate to a new technical implementation of a mathematical operation (e.g. in effect a new and beneficial way of performing mathematical operations or “computing” using a device – sometimes called “core” inventions)?
A positive answer in the first case, suggests a quick check against the provided examples and the case law to determine if the specific engineering application has in the past been deemed to be “technical” under European practice.
A positive answer in the second case suggests looking carefully at the constraints imposed by the electronic hardware of the implementation. You will need to describe how the mathematical method is adapted, e.g. as compared to a “text-book” application, to provide concrete implementational improvements.
Artificial Intelligence and Machine Learning
Sub-section 3.3.1 is relatively short and seeks to summarise existing case law that applies in this area. This anticipates a large rise in patent applications over the coming years.
Machine learning inventions have been patented at the European Patent Office almost since its inception in the late 1970s. The present sub-section reminds us that despite the recent resurgence in neural networks, algorithms for approaches such as “classification, clustering, regression and dimensionality reduction” including “genetic algorithms, support vector machines, k-means, kernel regression and discriminant analysis” have been around for a number of years.
The sub-section stresses that the algorithms and approaches themselves per se of an abstract mathematical nature. The guidance from section 3.3 therefore applies: the invention either needs to relate to a specific engineering application that uses the approaches (e.g. using k-means clustering to classify packets in a network for selective filtering) or a new technical implementation of the approach that is constrained by technical factors at least the underlying computation hardware.
The sub-section hints that “technical character” often requires a clear causal link to measured data that represents physical phenomena. For example, classification of digital data such as physiological measurements, images, videos, or audio data is seen to be a common “technical application”. However, classifying text data is regarded as a “linguistic” and “non-technical” application. Likewise, general classification of “data” or “records” without a link to a specific technical problem would likely be seen as “non-technical”. Reference is made to case T 1358/09.
The sub-section ends by indicating that if a classification method is seen to serve a technical purpose then the steps of generating the training set and training the classifier may also contribute to the technical character of the invention if they support the technical purpose. This provides useful advice for drafting claims for inventions in this area: it is recommended to consider independent claims to the generation of training data and architecture training, as well as claims to an inference step. These claims may also provide a distributed processing system as discussed in section 3.3, for example inference may be performed on a smartphone, whereas data cleaning and training may be performed on a remote server. Care should be taken to cover different infringing acts.
Simulation, design or modelling
Sub-section 3.3.2 draws out material that was present in section 3.3. Discussing this material in a separate sub-section clarifies the high-level overview now present in section 3.3.
A computer-implemented simulation of a specific technical system or process may be seen to provide a technical effect and lead to a granted European patent. However, objections will be raised to computer-implemented simulations of non-technical systems or processes, such as those with an aim in the fields of finance, marketing, administration, scheduling or logistics. Care should be taken; cases such as T 531/09 indicate that the presence of technical devices (X-ray scanners in that case) is not enough to provide technical character, the technical devices need to be specific devices and the simulation needs to perform a technical purpose.
In the field of computer-aided design, the determination of a technical parameter which is intrinsically linked to the functioning of a technical object, where the determination is based on technical considerations, is a technical purpose. For example, a method of determining a particular value for a parameter of a specific technical device, in a manner that improves production or use of the device may be seen as suitably “technical”. Care should be taken if the design involves decisions to be made by a human being – e.g. the selection of an approved value – this intervention may be seen to break a causal chain that connects the design method to a technical purpose. Such decisions also risk importing factors that are outside of a narrow determination based on “technical considerations”.
Finally, this new sub-section suggests that claims that produce “models” will often lead to objections on the grounds that the models are not technical features per se; instead, they are seen as “abstract” mathematical or mental features. This again complements current practice in the United States. It is emphasised that generation of a model may be considered to lack a technical effect, even if the modelled product, system or process is technical. It this case it is important that the claim clearly indicates how the model is used, or to be used, in a technical system or process to solve a technical problem.
Business Methods
The previous high-level summary in section 3.5 has now been deleted, with this material being moved into separate sub-sections related to each of “performing mental acts”, “playing games” and “doing business”. Each sub-section then contains new material relating to each sub-category.
Each sub-section begins with a useful definition of each exclusion. Although this is described in the context of the exclusion being applied to the whole claim (e.g. the exclusion applying “as such” or “per se”), this often will not occur in practice, e.g. in most cases the exclusions set out in Article 52(2)(c) EPC will be avoided by having the method performed by a computing device. However, the definitions are useful as they indicate which claim features may be ignored for inventive step on the grounds that they provide no technical effect.
Mental Acts
These are described as instructions to the human mind on how to conduct cognitive, conceptual or intellectual processes. The learning of a language is given as an example, which hints at how the European Patent Office legally support an objection to “linguistic” features (e.g. text processing) as being non-technical.
When drafting claims to computer-implemented inventions, especially method claims, care should be taken to avoid accidentally falling within the exclusion. For example, claims should be checked to ensure that the method steps therein cannot be performed entirely in the human mind; at least one step needs to be performed outside of the human mind. In practice, considering whether a method step can be performed in the human mind is useful when predicting whether inventive step objections may be issued during European examination; if the determination is positive, the method step can often be drafted or amended in a manner that avoids this interpretation, e.g. by referring to a specific technical apparatus. The sub-section indicates that a method would not be seen as performing mental acts if it requires the use of technical means or if it provides a physical entity as a resulting product.
The sub-section does not indicate that mental steps are necessarily ignored for an analysis of inventive step; however, it does emphasise that are mental steps must contribute to producing a technical effect that serves a technical process. A good example provided in the sub-section is that of affixing a driver to a Coriolis mass flowmeter: steps specifying the position of the driver may be performed mentally but by defining the position so as to maximise the performance of the flowmeter, a technical contribution is provided.
Games
Games are defined in sub-section 3.5.2 as a conceptual framework of conventions and conditions that govern player conduct and how a game evolves in response to decisions and actions by the players. Games are governed by game rules, that are by their nature abstract, mental entities that are only meaningful within a game context. Games may be simple – matching random numbers – or complex – video games with extensive virtual game worlds.
If a claim sets out technical means for implementing the rules of a game, it is not excluded as such and analysis moves onto inventive step. To provide an inventive step, a claim feature must make a technical contribution, i.e. provide some engineering benefit beyond a mere computer-implementation of the game rules. The benefit of a claim feature is to be assessed from the point of view of an engineer or game programmer, who may be given the games rules by a game designer as a “requirements specification”.
The sub-section indicates that in many situations the burden is on the applicant to show that a gaming invention provides a real engineering benefit. It notes that abstracting non-technical game elements, relying on a complexity of a solution or indicating cognitive content will not help the applicant.
It is interesting to compare the general negativity of this sub-section with cases such as T 928/03 and T 12/08 that presented a more liberal view of the technical nature of gaming inventions. It will be seen whether they represent a narrower approach than seen in the past.
Doing Business
Doing business is defined in sub-section 3.5.3 as including activities which are of financial, commercial, administrative or organisational nature. The latter two areas should be noted; they are often overlooked as they do not directly relate to making a profit but are still seen to be “non-technical”.
Some useful examples of “business method” features are provided. They include:
banking,
billing,
accounting,
marketing,
advertising,
licensing,
management of rights and contractual agreements,
legal activities,
personnel management,
workflows,
scheduling of tasks,
logistics,
organisational rules,
operational research,
planning, forecasting,
business optimisation, and
data science for the purpose of managerial decision making.
If an invention relates to any of these features, it should be assumed to relate to excluded subject matter unless there is strong evidence that a technical problem is being solved by a technical solution that involves technical considerations.
For practitioners, a disclosure document or inventor from industry will often present an invention in terms of a commercial benefit. For example, inventors often become familiar with internally promoting an invention on commercial grounds. Care should be taken to dig behind these grounds and return to the underlying engineering aspects of the idea. If no engineering aspects can be presented, the idea may not be suitable for a European patent application. Examiners and Boards of Appeal will also use an indication of a commercial benefit, or the presence of the above business features, as evidence of a lack of a technical contribution. For this reason, it is recommended to avoid discussing these when drafting the patent specification.
Programs for Computers
Section 3.6 has now been redrafted and sub-sections 3.6.1, 3.6.2, and 3.6.3 have been added to respectively cover “further technical effects”, “information modelling” and programming, and “data retrieval, formats and structures”.
Section 3.6 now begins by indicating that computer programs must produce a “further technical effect” to avoid exclusion on the grounds of being a computer program “as such”. A “further technical effect” is an effect that goes beyond the normal operation of a computer, e.g. the physical effects of executing a computer program. Controlling a technical process or the internal functioning of a computer or its interfaces are deemed to be valid “further technical effects”.
Although not explicitly indicated in section 3.6, it is relatively straightforward to demonstrate a “further technical effect” and avoid an objection to the whole claim under Articles 52(2)(c) and (3) EPC. For example, claims to a computer program may be said to provide a “further technical effect” if they include instructions to implement a technical method, e.g. if they indicate a dependency to an independent method claim that is deemed technical. In this manner, European patent applications often feature claims to a “computer program for implementing the method of claim X”.
Further technical effects that may be demonstrated by a computer program are set out in sub-section 3.6.1. These include:
controlling a technical system or process (e.g. a braking system of a car or an X-ray device);
data processing in any of the areas highlighted in section 3.3, e.g. audio/visual processing, encryption or compression;
improving the internal functioning of a computer running the program, e.g. programs that are adapted for a specific architecture or that provide benefits at the kernel or operating system level; and
providing low-level tools such as compilers, memory allocators, and builders.
This updated section and its sub-sections are more useful in indicating what kind of features may be deemed to provide a technical effect. For example, if a feature of a computer program is deemed to provide a “further technical effect” as set out in this section, the feature would be seen as “technical” and be counted in any evaluation of inventive step (e.g. for other independent system or method claims).
Information Modelling and Programming
Sub-section 3.6.2 now provides useful guidance when the invention relates to aspects of computer engineering or software in itself, e.g. as opposed to a computerised solution in another field of engineering. While software developers may assume that their solution is technical according to the normal use of that term, features may not actually be “technical” for the requirements of patentability.
Information modelling is defined here as relating to providing a formal description of a real-world system or process. It may be seen to relate to models built in graphical or textual modelling languages, such as the Unified Modelling Language (UML) or the Business Process Modelling Notation (BPMN). Information Modelling may result in data models or templates that represent an underlying process.
Programming is defined as relating to the way in which computer code is written. It can involve choosing certain options or conventions for performing a common functional operation, or defining and providing a programming language, including text-based or graphical systems.
This sub-section stresses that information modelling or programming features that improve the intellectual effort of a programmer or software developer will often be seen to lack technical character and so cannot contribute to an inventive step. Benefits such as re-usability, platform-independence, conciseness, easier code-management or convenience for documentation, are not regarded as technical effects. For a feature to provide a technical effect, it must provide an improvement from the viewpoint of the computer, as opposed to the programmer. For example, manipulating machine code to provide for greater memory efficiency is seen as providing a technical contribution.
Data retrieval, formats and structures
Computer-implemented data structures or data formats embodied on a medium or as an electromagnetic carrier wave may be claimed, as they do not fall within the exclusions of Article 52(2) EPC. This sub-section has been relocated from previous section 3.7.
This section emphasises that cognitive data, i.e. data that is only relevant to a human user, cannot normally contribute to an inventive step. However, functional data, i.e. data that controls a device processing the data and that reflects technical features of the device, can.
Some examples of functional data are provided. These include a picture encoding, an index structure for a relational database, or a header structure of an electronic message. It is emphasised that the actually data content of the picture, database record or electronic message is often seen to be cognitive content and so cannot contribute to an inventive step.
In advance of IP Inclusive’s Women in IP Flexible Working & Career Breaks Event, this post sets out some of the things I learnt taking a career break (shared parent leave) and working part-time. I hope it may be useful for others considering “off piste” career options.
For context, I have stuck my route through this whole thing at the bottom. Although I come at it from the point of view of a patent attorney, many points apply to other roles within the intellectual property (IP) profession, including paralegals, searchers, examiners, “back-office” roles, and IP solicitors.
Another disclaimer: these are my own views and not necessarily those of my employers present or past. You may also disagree; I am open to (polite!) discussion in the comments below.
As everyone likes “listicles” (or so say the £300/hour marketing consultants), I have decomposed my experience into ten key points:
There is no “official” path
You are lucky
Switch your view
You have a choice, but you can’t have it all
Time = Money = Career
The Patriarchy is accidental
Two is better than one
There is life outside of London
Remote working works
Imperfect Balance
Intrigued? Let’s have a look.
There is no “official” path
Photo by Skitterphoto on Pexels.com
When I first entered the world of intellectual property there seemed to be a well-defined structure: start in a junior role, put in the hours, work your way up to a senior role and a larger salary, work for another 20 years, get a gold clock and hope you have a defined benefit pension scheme.
This world is changing. Maybe it didn’t really exist at all. Assumptions are being called into question. The opening up of the workplace to a wider variety of backgrounds, together with general societal trends, means that people are taking a different, more realistic, and in many ways healthier, approach to work and careers.
Work for long enough and you too may see the cracks in the traditional narrative. Staff leave and join. Things you assumed were part of a “life path”, like housing or good health may no longer be available. Over the water-cooler or a networking pint, you hear whispers of others “doing something different”. You see people get lucky and unlucky rolls of the dice. You begin to learn that there are other possibilities, and that the hardest part is often imagining them.
The Internet and social media is a great help with this. You can see people move around on LinkedIn, post about their experiences on blogs such as this, or comment on Twitter.
Start with honesty. If things don’t seem to be working, try to work out why and don’t assume that there is a set structure or path you need to follow. Reach out to others in your employment, or via social media, to see what other routes there may be. Don’t be afraid to chat things through informally with your employer, line manager or a member of human resources; in my experience any fear I had was misplaced and people genuinely want to find something that works for everyone.
You are lucky
Photo by Anthony on Pexels.com
If you are working in the world of IP, you are lucky. This applies regardless of your role.
Don’t believe me? If you work in private practice, you can look up the accounts of patent and law firms for free at Companies House. You will see that these businesses do not operate with food-production or milk-farmer level margins. Technology companies also tend to be better placed in the economy than other sectors, such as retail. Yes there are worse years and better years, but look at annual profits or average partner remuneration (spoiler: private practice averages are somewhere between £200k and £500k). The patent profession is “effectively a legal cartel” (quoting Sir Colin Birss).
This means that there is more monetary slack in the system than there may be in other industries. The skills of all roles are in high demand. This put employees in a good negotiating position. Firms and companies need to retain trained staff, and most firms and companies are always looking for more staff. Use this to your advantage. You have the margin to be brave in your choices.
Switch your view
Photo by Pixabay on Pexels.com
That being said, businesses need to be run, and they need to make a profit. I’ve been on both sides of the managerial chair. If you want to branch out beyond the normal 9-5 employment contracts, your options also need to make managerial and financial sense for those you are working for. In an ideal world, it would be nice to live an idle life on law firm partner pay. But we can’t all be Jacob Rees-Mogg.
A good place to start is to work out your cost to your employer or to those using your services. Think about how your employer affords your salary or pay. In private practice, income comes from invoicing clients. In industry, a department may have an annual budget, revenue targets and key performance indicators. Remember that you often cost more than the money you receive in your paycheck. There is tax, national insurance, employee benefits, office costs, training costs, pension costs, etc. etc.
Then think about how your activities fit into the value chain. Docketing or paralegal cost may be charged as a “service fee” or have a budgeted amount per case. How much of your effort is required per work type? How much do you need to be paid to cover your personal expenses? How many hours do you have available per day? What seems like a endless series of choices can be whittled down to a practical proposal.
For employers, “flexible working” and “career breaks” have often been viewed with distrust. It was thought that employees could not be trusted, that flexible workers were too “difficult” to manage, or that the bottom line would fall. None of this has really come to pass. Indeed, the more astute employers are realising that in a field where there is a large demand for skills, offering flexibility can be a great selling point. Work/life balance was recently voted the most important concern for attorneys, above salary. Turns out wealth isn’t everything, who would have guessed? Beyond recruitment, a flexible workforce can also benefit the bottom line, helping get the day jobs done and freeing up in-house attorney time. The legal market is stretching vertically and approaches traditionally applied by counsel in industry to manage outside counsel are now being applied by law firms to manage virtual teams.
You have a choice, but you can’t have it all
Photo by Moose Photos on Pexels.com
In my experience, running one or more households and caring for one or more human beings is a full-time job. Trying to wish otherwise is unrealistic. The choice comes in the form of the person (or persons) doing this job. It could be:
one person full-time without pay (e.g. the traditional “houseperson” or grandparent);
two people part-time without pay (e.g. two freelancers or a “second job” + grandparent or sibling);
one person full-time with pay (e.g. a childminder or full-time carer); or
one person doing this part-time without pay and one person doing this part-time with pay (e.g. the also semi-traditional “second job” + “help”).
The person could be a parent, a child, a family member, or a friend.
For some the choice may not be much of a choice. Each person has a different set of circumstances. Some options may be easier than others. Many options may only be options if something is given-up or bartered. Having your cake and eating it is like a free-lunch, you are paying somewhere, it just may not be obvious at first sight. These may not be as intuitive as you think they are.
What you can’t try to wish out of existence is the caring role itself. I like to view carer roles like physicists view dark matter – just because you don’t see them doesn’t mean they are not there. It is a cliché (but true) that for every person with external responsibilities working 12-hour days there are others that we do not see working hard, and we may never directly see this effort. It seems tragic that it is only recently we are being to talk about how these roles are divided, and realising that a majority of the population may have an opinion on the matter that differs from our expectations.
Time = Money = Career
Photo by Pixabay on Pexels.com
Once you have set out the demands of your external responsibilities, your job responsibilities and your expenses, you can start to map the options available to all parties in a household.
Three levers you can vary are: time, money and career. These are interconnected. You can have more time, but this may come at a literal cost to your wallet and a figurative cost to your career (or at least a certain image of your career). You can have higher pay, but you may have less time.
You may have more control over these than you think. Most people think of money and career as a one-way street (for the patent attorneys: “a monotonically increasing function“). Looking at the hours many senior staff put in, as you rise in your role, your “free” time also diminishes. Many of us know senior partners in law firms or department managers that are checking their emails while on holiday or in the evenings. This email time is time that is not available for a role caring for other human beings, or doing household chores, or taking up a hobby, or volunteering in a local group. Time is a fixed quantity. Remember the cost is not always visible.
In negotiations for flexible working do not be afraid to trade salary for time. If you have fewer hours available per week, e.g. because you have to care for a child or relative, this will mean you can work fewer hours per week. However, make sure that you are not being paid less for the same work. Look at the value your work provides your employer – for a paralegal this may be charged out directly, for an IT support role this may be indirectly charged out as patent attorney or paralegal time (if the computers stopped working no one could charge anything). This may be harder for roles in industry than for private practice, but you may find a costing for IP in an annual review or a licensing income you can use to justify your value. You may feel a bit besmirched putting everything in monetary terms but remember this is not your value, it is just a representation of your value for dealing with an entity whose purpose is monetary (to make a profit). You can increase your chances of success by playing the game. You can also play around with the figures, and mock up different scenarios.
The Patriarchy is accidental
Photo by Jan Kroon on Pexels.com
In private practice, most law firms have a heavily male partnership. Roles in industry are better, and it is good to see Women in IP highlighting senior female figures in IP, but there is still a male skew (evidence: attendees at CIPA Congress 2018). There is also a female skew to paralegal roles. Some believe this is driven by unintelligent design; I’m more of the opinion this is a historical accident that is open to change.
Now I’m not going to take on what is a huge issue, and walk briskly into a minefield. But I can just about see how a heavy-male skew in senior patent attorney roles can arise. First there is a bias towards men working in science and engineering (one I’m trying to reverse with my parental nudging to my daughters). Second to enter partnership in private practice you need to work hard and have excellent billing figures. The time many enter partnership also overlaps with the time that many start a family (30-40s), or if you have older parents, manage their ageing. Even at the most progressive patent firms, partnership and a 3-day week is generally not an option. To be fair, it is difficult (impossible?) to provide full 24-hour service to demanding clients and provide full 24-hour service to demanding children. Cultural bias, breastfeeding, self-affirming networks, the need to physically recover after birth, and the need to pay the bills all conspire to nudge the pinball of life towards traditional male-female caregiver roles. Now just because something is, doesn’t mean it should be. A first step is awareness; a second step is change. I receive many a confused look from men when I ask them whether they are willing to give up their own career development for a time to allow their partner to rise up through the ranks. Normally this is excused on monetary terms: we couldn’t afford it. Forgive my scepticism, but in the patent world this can come from people earning six-figure salaries. The average UK full-time salary is below £30,000 (gross).
Once you see the random trail of the pinball you can take more control over its direction. As a business owner or employer you can make the playground equal to allow both men and women to take time off. You can change how work is performed to make it easier to distribute work in a piece-meal fashion, facilitating flexible working. Men can realise that they may need to adjust their perceived route through life, that there are other paths. We can all switch off our phones at 5:30pm.
Two is better than one
Photo by Mikey Dabro on Pexels.com
In you live in a two-parent household, we found that having two people work part-time or flexible roles is better than the traditional breadwinner / houseperson split. In purely financial terms, in the UK, you can be 15-20% better off with this arrangement, based on tax rates and penalties regarding child benefit and childcare.
Having two people work part-time can also allow a career to be pursued to a lesser extent by both parties, rather than requiring the traditional sacrifice from one half of the household. This has benefits outside of pure employment. For example, the experiences of both parties are closer, which reduces resentment and facilitates understanding.
For the partner used to working long office hours, there are benefits to stepping off the pedal and taking on more of the unpaid household tasks. Dropping the kids off at school or childcare allows you to become involved in your local community, and move out of a workplace or professional bubble. It is very easy to get caught up in a world of work, but such a world is fairly brittle. If the unexpected or unwelcome hit, they often hit hard. Working flexibly or part-time allows you to build up social capital that can make you more resilient.
Bronnie Ware, an Australian palliative nurse, noted that one of the top regrets of dying male patients was “I wish I hadn’t worked as hard”.
There is life outside of London
Photo by Lukas Hartmann on Pexels.com
*A collective gasp is heard along Chancery Lane*
Live in or around London and London often seems like life. It is not. There are IP roles outside of London. Not all large businesses have their headquarters in London. There are private practice offices in most UK university towns.
Living outside of London could half your housing and living costs, with a smaller proportional drop in salary. You could move somewhere where you can walk or cycle to work. Work outside of London and you can avoid commutes that clock up as an hour each way with what seems like the entire population of Denmark. Yes, there is less culture, fewer venues, galleries and restaurants, but have three kids and you rather quickly end up going to bed at 9pm and a walk to the shops resembles a military exercise. You are also not confronted with raging inequality that takes mental effort to filter out and rationalise everyday.
Remote working works
Photo by Negative Space on Pexels.com
When I started in the profession we were only just beginning to receive instructions by email. This was seen as “something not quite right”. Post (or perhaps facsimile transmission) was “how things were done”. People shuffled between patent firms and the London post branch of the UK Patent Office with brown-wrapped parcels. Work literally piled up in front of you.
In over a decade much of this has changed. Working can often feel like the film Inception as I dive into virtual machines within virtual networks within virtual machines. You can file a patent application from anywhere in the world. You can receive all communications electronically. Online file and docketing systems manage files and due dates in the cloud. Everyone loves Microsoft Word (okay that one isn’t great).
One of the panel at the Women in IP event, and an ex-colleague, spent a year working as a patent attorney while circumventing the globe. I know of patent attorneys who work for UK firms that do not live in the UK.
As a slight caveat, I am relatively IT-savvy. But I was surprised at the ease with which I could work outside of the office on a laptop or computer. All you need is good WiFi. Do not be afraid.
Imperfect Balance
Photo by Magda Ehlers on Pexels.com
Life often seems to me like a Necker Cube. Look at it one way and you are a total failure, miserably falling short of your true potential. Flip your frame of reference and you are a wild success, much better off than most of humanity, alive or dead. Both may be true. No one can know for sure.
You have to be realistic. I spend much more time with my kids that many dads. But this doesn’t mean we live in Von Trappian bliss. If anything I probably get cross at my kids more than the average bedtime or weekend dad. Much of my day can pass in domestic drudgery (washing, dishes, shopping, cooking, ferrying; then repeat). But I feel richer than a Partner in a London law firm.
Human beings have known for over two and a half millennia that truth and success lie in a middle way. But this is hard because our desires, inclinations and habits pull us to the poles. You need to exert effort to stay balanced. Like riding a bike. Knowing how to do this takes years and is a skill you acquire. It doesn’t arrive by magic.
Working flexibly, taking a career break or changing your career may need you to give up certain things. But you can gain other things that can provide a path of fulfilment that may not be visible in life’s melee.
My Route
Note: Mess and the CIPA Journal
I started off my career on the well-trodden patent attorney path. In my last year of university I sent off my letters to most of the patent firms in the Inside Careers guide, and ended up being lucky enough to be accepted for a training place at Gill Jennings & Every (GJE). Things went pretty smoothly for the first few years: I had success on the QMW Diploma course and the European Qualifying Examinations, and was progressing nicely within the firm. I got married and we were looking at buying somewhere to live in Wood Green. Then life, as it does, threw a few curve balls.
First, the “Great Recession” hit. Suddenly work started to dry up, and recruitment froze. It didn’t feel like a huge event at the time, but in hindsight it was clear that a general feeling of uncertainty and chaos hung around. Second, a close friend tragically died. She was a high-flying trainee lawyer. Although officially unrelated, I couldn’t help feel that the all-night working sessions and London lawyer lifestyle were somehow implicated. Third, my first daughter was born. There were complications with the birth, which shall we say “didn’t go well”, and she ended up in Intensive Care for a couple of weeks with possible brain damage. Luckily she appears fine now, 8 or 9 years later, but at the time we didn’t know whether there were going to be learning difficulties or other problems growing up.
This led us to look to leave London and to move closer to my (relatively large) family that lived in central Somerset. Bristol and Bath both had patent attorney firms and I sent the feelers out amongst the recruitment consultants. I ended up at EIP in Bath. We lived between family in Somerset and a family friend’s flat in Bath until we were lucky enough to find a small terraced house in Bath (any spelling mistakes are due to the lead paint and asbestos tiles I removed – we’re still there now).
Relatively quickly I was back on the career track, although now one slightly askew from the London mainline. My second daughter came along and I was eyeing up partnership in the distance along the classic lines. We tried to juggle parenting as best we could but ended up falling back onto rather typical binary roles (me at work until 6-7pm many nights, the other half being the default for the kids). Just after the birth of my second daughter, my father-in-law died suddenly, which shook us up a bit. My partner had a relatively small family, which was now even smaller, whereas I was used to large families down in Somerset. We thus decided to have one more.
At this time we began to look again at our parenting roles. Neither I nor my partner were particularly enjoying the long stressful hours (which were actually fairly tame by London standards), and the standard career route for me was for this all to become worse (for at least 10 years working up through the lower rungs of partnership). My partner enjoys her work and wanted to do more of it, but this meant days away once or twice a month that I often had to take as annual leave. It just so happened that it was at this time that the shared parental leave scheme came into force. It looked perfect.
In the end I applied to take 7 months shared parental leave while my partner took 2 months. I also put in a flexible working request for my return, to go down to 3 days a week. Both were granted (there wasn’t much choice on the first). Work was really good about things but as the scheme was in its infancy I ended up helping with human resources on the form of the policy. The downside was that the pay was just statutory. This meant going down to around £550/month for 7 months. All non-essential bills were cut, all food shops were Lidl (and still are), and any bills that could be frozen were. (In hindsight I should have asked for some pay during this period, at least matching the maternity schemes and possibly going beyond, trading this for an agreement to work for a particular length of time on my return.)
In any case the shared parental leave worked fairly well. There was a lot less pressure on my partner than the previous two. I could do the night shifts and the sleep training (think waking up every hour throughout the night for several months) without collapsing at work the next day. There was no need to drag a baby to the school and nursery drop offs. The drop in income was mitigated slightly by the fact you can’t really go out or do anything with three kids.
Flexible working also worked, to a certain extent. It felt a little split-brain – three days a week life was back to pre-parental leave days, being in the office and dealing with the day-to-day; then two days a week, I was plunged into the world of chores, kid juggling, and dirty nappies. The cognitive dissonance is sometimes hard. I wrote a bit about it here. Flexible working allowed my partner to work longer or non-standard hours on the other two days.
As the sleeping began to improve I looked at moving up to working four days a week to get back onto a partnership track. However, after a few months we found this wasn’t really working. The kids each needed to be in different locations at varying times between 8:30am and 9:30am, and to be picked up at times that span from 12:30pm to 4:30pm. Working four days a week meant that the workload crept back up to a 8:30am to 6:30pm working day – with commuting time this meant I was out for much of the time the kids were awake. Parenting is a zero-sum game and so someone else needed to be there when I was not there. A nanny or childminder was not an option when we looked at our after tax salaries. My parents have nearly a decade before they retire and my partner’s mother lives three hours away. I started chatting to and reading about others in similar situations – both in real-life and online. Becoming a consultant for a consultancy firm seemed an option. I had two very useful conversations with ex-colleagues, they were a great help explaining how things could work. Also what was the partnership everyone was aiming at, if not being your own boss? I decided to bite the bullet and start my own consultancy business in December 2017. I now work preparing patent drafts and office actions for various clients on a job-by-job basis.
My current arrangement is the best I have. I have traded off income for time. I can now do school and nursery pick-ups and drop offs. My partner can spend days away without a PhD in logistics. The income-time trade-off isn’t as linear as it seems: e.g. being around more means I can spend an hour at 4pm cooking tea from simple ingredients so a meal for 5 costs £2.50 rather than £25, in effect saving £22.50 after-tax. This is found in many other areas. Another is that I now have no commute, so I don’t need to pay £7000 after tax per year just to work. I can also choose to work hard on billable jobs one week, then have less paid work the next week to “work” on enjoyable not directly billable tasks such as this blog post, or processing 292,000 G06 US patent specifications.
As a caveat. It is still early days. It could all go disastrously wrong. I hope it doesn’t.
When working with neural network architectures we need good datasets for training. The problem is good datasets are rare. In this post I sketch out some ideas for building a dataset of smaller, linked portions of a patent specification. This dataset can be useful for training natural language processing models.
What are we doing?
We want to build some neural network models that draft patent specification text automatically.
In the field of natural language processing, neural network architectures have shown limited success in creating captions for images (kicked off by this paper) and text generation for dialogue (see here). The question is: can we get similar architectures to work on real-world data sources, such as the huge database of patent publications?
How do you draft a patent specification?
As a patent attorney, I often draft patent specifications as follows:
Review invention disclosure.
Draft independent patent claims.
Draft dependent patent claims.
Draft patent figures.
Draft patent technical field and background.
Draft patent detailed description.
Draft abstract.
The invention disclosure may be supplied as a short text document, an academic paper, or a proposed standards specification. The main job of a patent attorney is to convert this into a set of patent claims that have broad coverage and are difficult to work around. The coverage may be limited by pre-existing published documents. These may be previous patent applications (e.g. filed by a company or its competitors), cited academic papers or published technical specifications.
Where is the data?
As many have commented, when working with neural networks we often need to frame our problem as map X to Y, where the neural network learns the mapping when presented with many examples. In the patent world, what can we use as our Xs and Ys?
If you work in a large company you may have access to internal reports and invention disclosures. However, these are rarely made public.
To obtain a patent, you need to publish the patent specification. This means we have multiple databases of millions of documents. This is a good source of training data.
Standards submissions and academic papers are also published. The problem is there is no structured dataset that explicitly links documents to patent specifications. The best we can do is a fuzzy match using inventor details and subject matter. However, this would likely be noisy and require cleaning by hand.
US provisional applications are occasionally made up of a “rough and ready” pre-filing document. These may be available as priority documents on later-filed patent applications. The problem here is that a human being would need to inspect each candidate case individually.
Claim > Figure > Description
At present, the research models and datasets have small amounts of text data. The COCO image database has one-sentence annotations for a range of pictures. Dialogue systems often use tweet or text-message length text segments (i.e. 140-280 characters). A patent specification in comparison is monstrous (around 20-100 pages). Similarly there may be 3 to 30 patent figures. Claims are better – these tend to be around 150 words (but can be pages).
To experiment with a self-drafting system, it would be nice to have a dataset with examples as follows:
Independent claim: one independent claim of one predefined category (e.g. system or method) with a word limit.
Figure: one figure that shows mainly the features of the independent claim.
Description: a handful of paragraphs (e.g. 1-5) that describe the Figure.
We could then play around with architectures to perform the following mappings:
One problem is this dataset does not naturally exist.
Another problem is that ideally we would like at least 10,000 examples. If you spent an hour collating each example, and did this for three hours a day, it would take you nearly a decade. (You may or may not also be world class in example collation.)
The long way
Because of the problems above it looks like we will need to automate the building of this dataset ourselves. How can we do this?
If I was to do this manually, I would:
Get a list of patent applications in a field I know (e.g. G06).
Choose a category – maybe start with apparatus/system.
Get the PDF of the patent application.
Look at the claims – extract an independent claim of the chosen category. Paste this into a spreadsheet.
Look at the Figures. Find the Figure that illustrated most of the claim features. Save this in a directory with a sensible name (e.g. linked to the claim).
Look at the detailed description. Copy and paste the passages that mention the Figure (e.g. all those paragraphs that describe the features in Figure X). This is often a continuous range.
The shorter way
There may be a way we can cheat a little. However, this might only work for granted European patents.
One bug-bear enjoyable part of being a European patent attorney is adding reference numerals to the claims to comply with Rule 43(7) EPC. Now where else can you find reference numerals? Why, in the Figures and in the claims. Huzzah! A correlation.
So a rough plan for an algorithm would be as follows:
Get a list of granted EP patents (this could comprise a search output).
Define a claim category (e.g. based a string pattern – [“apparatus”, “system”]).
Process the claims to locate the lowest number independent claim of the defined claim category (my PatentData Python library has some tools to do this).
If a match is found:
Save the claim.
Extract reference numerals from the claim (this could be achieved by looking for text in parenthesis or using a “NUM” part of speech from spaCy).
Extract paragraphs from the description that contain the extracted reference numerals (likely with some threshold – e.g. consecutive paragraphs with greater than 2 or 3 inclusions).
Save the paragraphs and the claim, together with an identifier (e.g. the published patent number).
Determine a candidate Figure number from the extracted paragraphs (e.g. by looking for “FIG* [/d]”).
Fetch that Figure using the EPO OPS “Drawings” or images retrieval API.
Now we can’t retrieve specific Figures, only specific sheets of drawings, and only in ~50% of cases will these match.
We can either:
Retrieve all the Figures and then OCR these looking for a match with the Figure number and/or the reference numbers.
Start with a sheet equal to the Figure number, OCR, then if there is no match, iterate up and down the Figures until a match is found.
See if we can retrieve a mosaic featuring all the Figures, OCR that and look for the sheet number preceding a Figure or reference numeral match.
Save the Figure as something loadable (TIFF format is standard) with a name equal to the previous identifier.
The output from running this would be triple similar to this: (claim_text, paragraph_list, figure_file_path).
We might want some way to clean any results – or at least view them easily so that a “gold standard” dataset can be built. This would lend itself to a Mechanical Turk exercise.
We could break down the text data further – the claim text into clauses or “features” (e.g. based on semi-colon placement) and the paragraphs into clauses or sentences.
The image data is black and white, so we could resize and resave each TIFF file as a binary matrix of a common size. We could also use any OCR data from the file.
What do we need to do?
We need to code up a script to run the algorithm above. If we are downloading large chunks of text and images we need to be careful of exceeding the EPO’s terms of use limits. We may need to code up some throttling and download monitoring. We might also want to carefully cache our requests, so that we don’t download the same data twice.
Initially we could start with a smaller dataset of say 10 or 100 examples. Get that working. Then scale out to many more.
If the EPO OPS is too slow or our downloads are too large, we could use (i.e. buy access to) a bulk data collection. We might want to design our algorithm so that the processing may be performed independently of how the data is obtained.
Another Option
Another option is that front page images of patent publications are often available. The Figure published with the abstract is often that which the patent examiner or patent drafter thinks best illustrates the invention. We could try to match this with an independent claim. The figure image supplied though is smaller. This maybe a backup option if our main plan fails.
Wrapping Up
So. We now have a plan for building a dataset of claim text, description text and patent drawings. If the text data is broken down into clauses or sentences, this would not be a million miles away from the COCO dataset, but for patents. This would be a great resource for experimenting with self-drafting systems.
I recently read an article by Professor Margaret Boden on “Robot Needs”. While I agree with much of what Professor Boden says, I feel we can be more precise with our questions and understanding. The answer is more “maybe” than “no“.
Warning: this is only vaguely IP related.
Definitions & Embodiment
First, some definitions (patent attorneys love debating words). The terms “robot”, “AI” and “computer” are used interchangeably in the article. This is one of the problems of the piece, especially when discussing “needs”. If a “computer” is simply a processor, some memory and a few other bits, then yes, a “computer” does not have “needs” as commonly understood. However, it is more of an open question as to whether a computing system, containing hardware and software, could have those same “needs”.
AI
This brings us to “AI”. The meaning of this term has changed in the last few years, best seen perhaps in recent references to an “AI” rather than “AI” per se.
In the latter half of the twentieth century, “AI” was mainly used in a theoretical sense to refer to non-organic intelligence. The ambiguity arises with the latter half of the term. “Intelligence” means many different things to many different people. Is playing chess or Go “intelligent”? Is picking up a cup “intelligent”? I think the closest we come to agreement is that it generally relates to higher cortical functions, especially those demonstrated by human beings.
Since the “deep learning” revival broke into public consciousness (2015+?) “AI” has taken on a second meaning: an implementation of a multi-layer neural network architecture. You can download an “AI” from Github. “AI” here could be used interchangeably with “chatbot” or a control system for a driverless car. On the other hand, I don’t see many people referring to SQL or DBpedia as an “AI“.
“AI” tends to be used to refer more to the software aspects of “intelligent” applications rather than a combined system of server and software. There is a whiff of Descartes: “AI” is the soul to the server “body“
Based on that understanding, do I believe an “AI” as exemplified by today’s latest neural network architecture on Github has “needs“? No. This is where I agree with Professor Boden. However, do I believe that a non-organic intelligence could ever have “needs“? I think the answer is: Yes.
Robots
This leads us to robots. A robot is more likely to be seen as having “needs” than “AI” or a “computer“. Why is this?
Robots have a presence in the physical world – they are “embodied“. They have power supplies, motors, cameras, little robotic arms, etc. (Although many forget that your normal rack servers share a fair few components.) They clearly act within the world. They make demands on this world, they need to meet certain requirements in order to operate. A simple one is power; no battery, no active robot. I think most people could understand that, in a very simple way, the robot “needs” power.
Let’s take the case where a robot is powered by a software control system. Now we have a “full house“: a “robot” includes a “computer” that executes an “AI“. But where does the “need” reside? Again, it feels wrong to locate it in the “computer” – my laptop doesn’t really “need” anything. Saying an “AI” “needs” something is like saying a soul “needs” food (regardless of whether you believe in souls). We then fall back on the “robot“. Why does the robot feel right? Because it is the most inclusive abstract entity that encompasses an independent agent that acts in the world.
Needs, Goals & Motivation
Before we take things further lets go on a detour to look at “needs” in more detail. In the article, “needs” are described together with “goals” and “motivation“. Maslow’s famous pyramid features. In this way, a lot is packaged into the term.
Maslow’s Pyramid – By Factoryjoe on WikiCommons
Can we have “needs” without “goals“? Possibly. A quick google shows several articles on “What Bacteria Need to Live” (clue: raw chicken and your kitchen). I think we can relatively safely say that bacteria “need” food and water and a benign environment. Do bacteria have “goals“? Most would say: No. “Goals“, especially as used to describe human behaviour, suggests the complex planning and goal-seeking machinery of the human brain (e.g. as a crude generalisation: the frontal lobes and corpus striatum amongst others). So we need to be careful mixing these – we have a term that may be applied to the lowest level of life, and a term than possibly only applies to the highest levels of life. While robots could relatively easily have “needs“, it would be more much difficult to construct one with “goals“. We would also stumble into “motivation” – have does a robot transform a “need” into a “goal” to pursue it?
Now, as human beings we instinctively know what “motivation” feels like. It is that feeling in the bladder that drives you off your chair to the toilet; it is the itchy uneasiness and dull empty abdominal ache that propels you to the crisp packet before lunch; it is the parched feeling in the throat and the awareness that your eyes are scanning for a chiller cabinet. It is harder to put it into words, or even to know where it starts or ends. Often we just do. Asked why we are doing what we do and the brain makes up a story. Sometimes there is a vague correlation between the two.
Now this is interesting. Let’s have a look at brains for more insight.
Brains
Nature is great. She has evolved at least the Earth’s most efficient data processing device (ignore that the “she” here also doesn’t really exist). Looking at how she has done this allows us to cheat a little when building robots.
A first thing to note is that nature is lazy and stupid (hurray!). She recycles, duplicates, always takes the easy option. This paradoxically means we have arrived at efficiency through inefficiency. Brains started out as chemical gradients, then rudimentary cellular architecture to control these gradients, then multi-cellular architectures, nervous passageways, spinal cords, brain stems, medullas, pons, mid-brains, limbic structures and cortex. Structures are built on top of structures and wired up in ways that would give an electrician a heart attack. Plus structures are living – they change and grow over time within an environment.
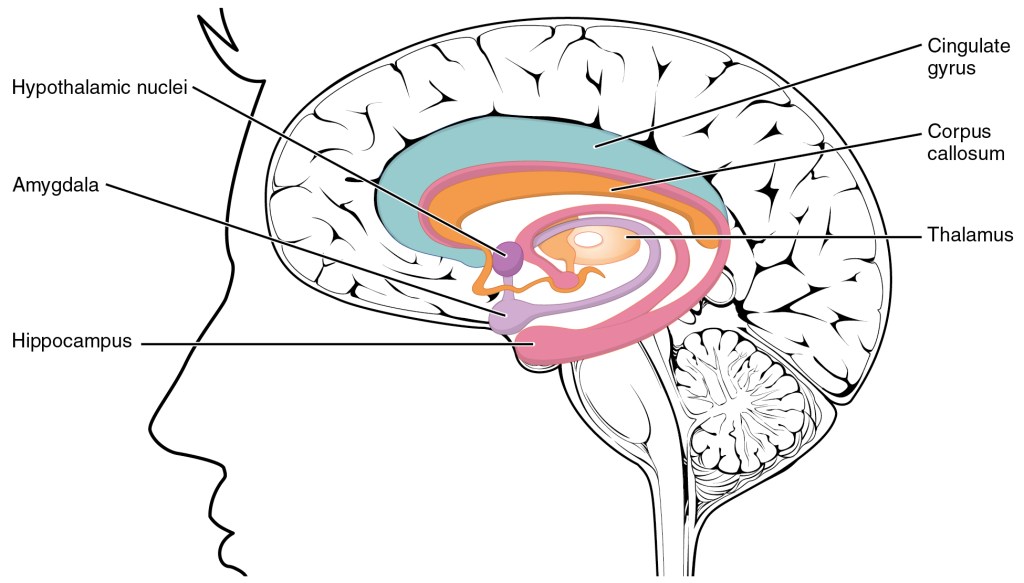
In the brain “needs“, at least those near the bottom of the Maslowian pyramid, map fairly nicely onto lower brain structures: the brain stem, medulla, pons, and mid-brain. The thalamus helps to bridge the gap between body and cortex. The cortex then stores representations of these “needs“, and maps them to and from sensory representations. Another crude and incorrect generalisation, but those lower structures are often called the “lizard brain“, as those bits of neural hardware are shared with our reptilian cousins. The raw feeling of “needs” such as hunger, thirst, sexual desire, escape and attack is possibly similar across many animals. What does differ is the behaviour and representations triggered in response to those needs, as well as the top down triggering (e.g. what makes a human being fear abstract nouns).
Lower Brain Structure – Cancer Research UK / Wikimedia Commons
Comparative studies of brain structure and development have revealed a general bauplan that describes the fundamental large-scale architecture of the vertebrate brain and provides insight into its basic functional organization. The telencephalon not only integrates and stores multimodal information but is also the higher center of action selection and motor control (basal ganglia). The hypothalamus is a conserved area controlling homeostasis and behaviors essential for survival, such as feeding and reproduction. Furthermore, in all vertebrates, behavioral states are controlled by common brainstem neuromodulatory circuits, such as the serotoneric system. Finally, vertebrates harbor a diverse set of sense organs, and their brains share pathways for processing incoming sensory inputs. For example, in all vertebrates, visual information from the retina is relayed and processed to the pallium through the tectum and the thalamus, whereas olfactory input from the nose first reaches the olfactory bulb (OB) and then the pallium.
“Needs” near the middle or even the top of Maslow’s pyramid are generally mammalian needs. These include love, companionship, acceptance and social standing. Consensus is forming that nature hijacked parental bonds, especially those that arise from and encourage breast feeding, to build societies. An interesting question is does this require the increase in cortical complexity that is seen in mammals? These “needs” mainly arise from the structures that surround the thalamus and basal ganglia, as well as mediators such as oxytocin. So that pyramid does actually have a vague neural correlate; we build our social lives on top of a background of other more essential drives.
The top of Maslow’s pyramid is contentious. What the hell is self-actualisation? Being the best you you can be? What does that mean? The realisation of talents and potentialities? What if my talent is organising people to commit genocide? Rants aside, Wikipedia gives us something like:
Expressing one’s creativity, quest for spiritual enlightenment, pursuit of knowledge, and the desire to give to and/or positively transform society are examples of self-actualization.
What these seem to be are human qualities that are generally not shared with other animals. Creativity, spirituality, knowledge and morality are all enabled by the more developed cortical areas found in human beings, as coordinated by the frontal lobes, where these cortical areas feed back to both the mammalian and lower brain structures.
A person may thus be likened to a song. The beat and bass provided by the lower brain structures, lead guitar and vocals by the mammalian structures, and the song itself (in terms of how these are combined in time) by the enlarged cortex.
Back to Needs
We can now understand some of the problems that arise when Professor Boden refers to “needs“. Human “needs” arise at a variety of levels, where higher levels are interconnected with and feed back to lower levels. Hence, you can take about “needs” such as hunger relatively independently of social needs, but social needs only arise in systems that experience hunger. There is thus a question of whether we can talk about social needs independent of lower needs.
We can also see how the answer to the question: “can robots ever have needs?” ignores this hierarchy. It is easier to see how a robot could experience a “need” equivalent to hunger than it is to see it experience a “need” equivalent to acceptance within a social group. It is extremely difficult to see how we could have a “self-actualised” robot.
Environment
Before we look at whether robots care we also need to introduce “the environment“. Not even human beings have “needs” in isolation. Indeed, a “need” implies something is missing, if an environment fulfils the requirement of a need, is it still a “need“?
Additionally, behaviour that is not suited to an environment would fall outside most lay definitions of “intelligence“. “Intelligence” is thus to a certain extent a modelling of the world that enables environmental adaptation.
Photo by icon0.com on Pexels.com
The environment comes into play in two areas: 1) human “needs” have evolved within a particular “environment“; and 2) a “need” is often expressed as behaviour that obtains a requirement from the “environment” that is not immediately present.
Food, water, a reasonable temperature range (10 to 40 degrees Celsius), and an absence of harmful substances are fairly fundamental for most life; but these are actually a mirror image of the physical reality in which life on Earth evolved. If our planet had an ambient temperature of 50 to 100 degrees Celsius, would we require warmth? Can non-hydrogen-based life exist without water? Could you feed off cosmic rays?
These are not ancillary points. If we do create complex information processing devices that act in the world, where behaviour is statistical and environment-dependent, would their low-level needs over with ours? At presence it appears that a source of electrical power is a fairly fundamental “robot” or “AI” need. If that electrical power is generated from urine , do we have a “need” for power or for urine? If urine is correlated with over-indulging on cider at a festival, does the “AI” have a “need” for inebriated festival goers?
The sensory environment of robots also differs from human beings. Animals share evolutionary pathways for sensory apparatus. We have similar neuronal structure to process smell, sight, sound, motor-feedback, touch and visceral sensations, at least at lower levels of processing complexity. In comparison, robots often have simple ultrasonic transceivers, infra-red signalling, cameras and microphones. Raw data is processed using a stack of libraries and drivers. What would evolution in this computing “environment” look like? Can robots evolve in this environment?
Do robots have “needs“?
So back to “robots“. It is easier to think about “robots” than “AI“, as they are embodied in a way that provides an implicit reference to the environment. “AI” in this sense may be used much as we use “brain” and “mind” (it being difficult with deep learning to separate software structure from function).
Do robots have “needs“? Possibly. Could robots have “needs“? Yes, fairly plausibly.
Given a device with a range of sensory apparatus, a range of actuators such as motors, and modern reinforcement learning algorithms (see here and here) you could build a fairly autonomous self-learning system.
The main problem would not be “needs” but “goals“. All the reinforcement learning algorithms I am aware of require an explicit representation of “good“, normally in the form of a “score“. What is missing is a mapping between the environment and the inner state of the “AI“. This is similar to the old delineation between supervised and unsupervised learning. It doesn’t help that roboticists skilled at representing physical hardware states tend to be mechanical engineers, whereas AI researchers tend to be software engineers. It requires a mirroring of the current approach, so that we can remove scores altogether (this is an aim of “inverse reinforcement learning“). While this appears to be a lacuna in most major research efforts, it does not appear insurmountable. I think the right way to go is for more AI researchers to build physical robots. Physical robots are hard.
Do robots care?
Do most “robots” as currently constructed “care“? I’d agree with Professor Boden and say: No.
Photo by Snapwire on Pexels.com
“Care” suggests a level of social processing that the majority of robot and AI implementations currently lack. Being the self-regarding species that we are, most “social” robots as currently discussed refer to robots that are designed to interact with human beings. Expecting this to naturally result in some form of social awareness or behaviour is nonsensical: it is similar to asking why flies don’t care about dogs. One reason human beings are successful at being social is we have a fairly sophisticated model of human beings to go on: ourselves. This model isn’t exact (or even accurate), and is largely implemented below our conscious awareness. But it is one up from the robots.
A better question is possibly: do ants care? I don’t know the answer. One one hand: No, it is difficult to locate compassion or sympathy within an ant. On the other hand: Yes, they have complex societies where different ants take on different roles, and they often act in a way that benefits those societies, even to the detriment of themselves. Similarly, it is easier to design a swarm of social robots that could be argued to “care” about each other than it is to design a robot that “cares” about a human being.
Also, I would hazard to guess that a caring robot would first need to have some form of autonomy; it would need to “care” about itself first. An ant that cannot acquire its own food and water is not an ant that can help in the colony.
Could future “robots” “care“? Yes – I’d argue that it is not impossible. It would likely require a complex representation of human social needs but maybe not the complete range of higher human capabilities. There would always be the question of: does the robot *truly* care? But then this question can be raised of any human being. It is also a fairly pertinent question for psychopaths.
Getting Practical
Despite the hype, I agree with Professor Boden that we are a long way away from any “robot” and “AI” operating in a way that is seen as nearing human. Much of the recent deep learning success involve models that appear cortical, we seem to have ignored the mammalian areas and the lower brain structures. In effect, our rationality is trying to build perfectly rational machines. But because they skip the lower levels that tie things together, and ignore the submerged subconscious processes that mainly drive us, they fall short. If “needs” are seen as an expression of these lower structures and processes, then Professor Boden is right that we are not producing “robots” with “needs“.
As explained above though, I don’t think creating robots with “needs” is impossible. There may even be some research projects where this is the case. We do face the problem that so far we are coming at things backwards, from the top-down instead of the bottom-up. Using neural network architectures to generate representations of low-level internal states is a first step. This may be battery levels, voltages, currents, processor cycles, memory usage, and other sensor signals. We may need to evolve structural frameworks in simulated space and then build upon these. The results will only work if they are messy.
If anyone wants to play with the legislation you can use the requests and Beautiful Soup libraries in Python to parse the XML. If you want a bit more power you can use lxml.
This article will look into how the process of obtaining a patent could be automated using deep learning approaches. A possible pipeline for processing a patent application will be discussed. It will be shown how current state of the art natural language processing techniques could be applied.
Brief Overview of Patent Prosecution
First, let’s briefly look at how a patent is obtained. A patent application is filed. The patent application includes a detailed description of the invention, a set of figures, and a set of patent claims. The patent claims define the proposed legal scope of protection. A patent application is searched and examined by a patent office. Relevant documents are located and cited against the patent application. If an applicant can show that their claimed invention is different from each citation, and that any differences are also not obvious over the group of citations, then they can obtain a granted patent. Often, patent claims will be amended by adding extra features to clearly show a difference over the citations.
Patent Data
For a deep learning practitioner the first question is always: what data do I have? If you are lucky enough to have labelled datasets then you can look at applying supervised learning approaches.
It turns out that the large public database of patent publications is such a dataset. All patent applications needs to be published to continue to grant. This will be seen as a serendipitous gift for future generations.
Search Process
In particular, a patent search report can be thought of as the following processes:
A patent searched locates a set of citations based on the language of a particular claim.
Each located citation is labelled as being in one of three categories:
– X: relevant to the novelty of the patent claim.
– Y: relevant to the inventive step of the patent claim. (This typically means the citation is relevant in combination with another Y citation.)
– A: relevant to the background of the patent claim. (These documents are typically not cited in an examination report.)
In reality, these two processes often occur together. For our ends, we may wish to add a further category: N – not cited.
Problem Definition
Thinking as a data scientist, we have the following data records:
This data may be retrieved (for free) from public patent databases. This may need some intelligent data wrangling. The first process may be subsumed into the second process by adding the “not cited” category. If we move to a slightly more mathematical notation, we have as data:
(c, d, s)
Where c and d are based on a (long) string of text and s is a label with 4 possible values. We then want to construct a model for:
P(s | c, d)
I.e. a probability model for the search classifications given the claim text and citation detailed description. If we have this we can do many cool things. For example, for a set c, we can iterate over a set of d and select the documents with the highest X and Y probabilities.
Representations for c and d
Machine learning algorithms operate on real-valued tensors (n*m -dimensional arrays). more than that, the framework for many discriminative models maps data in the form of a large tensor X to a set of labels in the form of a tensor Y. For example, each row in X and Y may relate to a different data sample. The question then becomes how do we map (c, d, s) to (X, Y)?
Mapping s to Y is relatively easy. Each row of Y may be an integer value corresponding to one of the four labels (e.g. 0 to 3). In some cases, each row may need to represent the integer label as a “one hot” encoding, e.g. a value of [2] > [0, 0, 1, 0].
Mapping c and d to X is harder. There are two sub-problems: 1) how do we combine c and d? and 2) how do we represent each of c and d as sets of real numbers?
There is an emerging consensus on sub-problem 2). A great explanation may be found in Matthew Honnibal’s post Embed, Encode, Attend, Predict. Briefly summarised, we embed words from the text using a word embedding (e.g. based on Word2Vec or GloVe). This outputs a sequence of real-valued float vectors for each word (e.g. vectors of length ~300). We then encode this sequence of vector into a document matrix, e.g. where each row of the matrix represents a sentence encoding. One common way to do this is to apply a bidirectional recurrent neural network (RNN – such as an LSTM or GRU), where outputs of a forward and backward network are concatenated. An attention mechanism is then applied to reduce the matrix to a vector. The vector then represents the document.
A simple way to address sub-problem 1) is to simply concatenate c and d (in a similar manner to the forward and backward passes of the RNN). A more advanced approach might use c as an input to the attention mechanism for the generation of the document vector for d.
Obtain the Data
To get our initial data records – (Claim text, citation detailed description text, search classification) – we have several options. For a list of patent publications, we can obtain details of citation numbers and search classifications using the European Patent Office’s Open Patent Services RESTful API. We can also obtain a claim 1 for each publication. We can then use the citation numbers to look up the detailed descriptions, either using another call to the OPS API or using the USPTO bulk downloads.
I haven’t looked in detail at the USPTO examination datasets but the information may be available there as well. I know that the citations are listed in the XML for a US grant (but without the search classifications). Most International (PCT / WO) publications include the search report, so as a push you could OCR and regex the search report text to extract a (claim number, citation number, search category) tuple.
Training
Once you have a dataset consisting of X and Y from c, d, s, the process then just becomes designing, training and evaluating different deep learning architectures. You can start with a simple feed forward network and work up in complexity.
I cannot guarantee your results will be great or useful, but hey if you don’t try you will never know!
In recent years there has been a resurgence of interest in machine learning and so-called “artificial intelligence” systems. Much of this resurgence is based on advances in so-called “deep learning”, neural networks with multiple layers of connections. For example, convolutional neural networks now provide state-of-the-art performance in many image recognition tasks and recurrent neural networks have been used to increase the accuracy of many commercial machine translation systems. Machine learning may be considered a subdiscipline of “artificial intelligence” that deals with algorithms that are trained to perform tasks such as classification based on collections of data. This recent resurgence has meant that more companies wish to protect innovations in this field. This quickly brings them into the realm of computer-implemented inventions, and the nuances of protection at the European Patent Office.
“Computer-implemented invention” is the European Patent Office term for a software invention. Claims that specify machine learning and artificial intelligence systems are almost certainly to be considered “computer-implemented inventions”. The innovation in such systems occurs in the design of the algorithms and/or software architectures. Claims for new hardware to implement machine learning and artificial intelligence systems, such as new graphical processing unit configurations, would not be classed as computer-implemented inventions and would be considered in the same manner as conventional computer devices.
What Do We Have To Go On?
As key advances in the field have only been seen since 2010, there are few Board of Appeal cases that explicitly consider these inventions. It is likely we will see many Board of Appeal decisions in this field, but it is unlikely these will filter through the system much before 2020. However, applications in the field are being filed and examined. The following review is based on knowledge of these applications, evaluated in the context of existing Board of Appeal cases.
Prior Art
A first issue regarding machine learning and artificial intelligence systems is that many of the underlying techniques are public knowledge, given the rapid turn-over of publications and repositories of electronic pre-prints such as arXiv. Hence, many applicants may face novelty and inventive step objections if the invention involves the application of known techniques to new domains or problems. For patent attorneys who are drafting new applications, it is recommended to perform a pre-filing search of such publication sources and ensure that the inventors provide a full appraisal of what is public knowledge.
Domain of Invention
A second issue is the domain of the invention. This may be seen as the context of the invention as presented in the claims and patent description.
Inventions that apply machine learning approaches to fields in engineering are generally considered more positively by the European Patent Office. These fields will typically either operate on low-level data that represents physical properties or have some form of actuation or change in the physical world. For example, the following domains are less likely to have features excluded from an inventive step evaluation for being “non-technical”: navigating a robot within a three-dimensional space; dynamic adaptive change of a Field Programmable Gate Array; audio signal analysis in speech processing; and controlling a power supply to a data centre.
On the other hand, inventions that apply machine learning approaches within a business or “enterprise” domain are likely to be analysed more closely. These inventions have a greater chance of claim features being excluded for being “non-technical”. These domains typically have an aim of increasing profit. The more this aim is explicit in the patent application, the more likely a “non-technical” objection will be raised. For example, the following inventions are more likely to have features excluded from an inventive step evaluation for being “non-technical”: intelligent organisation of playlists in a music streaming service; adaptive electronic trading of securities; automated provision of electronic information in a company hierarchy; and automated negotiation of online advertising auctions.
Exclusions from Patentability
A third issue that arises is that individual features of the claims fall within the exclusions of Article 52(2) EPC. In the field of machine learning and artificial intelligence systems, there is an increased risk of claim features being considered to fall into one of the following categories: mathematical methods; schemes, rules and methods for performing mental acts or doing business; and presentations of information. These will briefly be considered in turn below.
Mathematical Methods
The field of machine learning is closely linked to the field of statistics. Indeed many machine learning algorithms are an application of statistical methods. Academic researchers in the field are trained to describe their contributions mathematically, and this is required for publication in an academic journal. However, the practice of the European Patent Office, as directed by the Boards of Appeal, typically regards statistical methods as mathematical methods. In their pure, unapplied form they are considered “non-technical”.
Schemes, Rules and Methods for Performing Mental Acts
A claim feature is likely to be considered part of schemes, rules and methods for performing mental acts when the scope of the feature is too broad or abstract. For example, if a claimed method step also covers a human being performing the step manually, it is likely that the scope is too broad.
Schemes, Rules and Methods for Doing Business
Claim features are likely to be considered schemes, rules and methods for doing business when the information processing relates to a business aim or goal. This is especially the case where the information processing is dependent on the content of the data being processed, and that content does not relate to a low-level recording or capture of a physical phenomenon.
For example, processing of a digital sound recording to clean the recording of noise would be considered “technical”; processing row entries in a database of information technology assets to remove duplicates for licensing purposes would likely be considered “non-technical”.
Presentation of Information
Objections that features relate to the presentation of information may occur when the innovation relates to user experience (UX) or user interface (UI) features.
For example, a machine learning algorithm that adaptively arranges icons on a smartphone according to use may receive objections on the grounds that features relate to mathematical methods (the algorithm) and presentation of information (the arrangement of icons on the graphical user interface). As per Guideline G-II, 3.7.1, grant is unlikely if information is simply displayed to a user and any improvement occurs in the mind of the user. However, it is possible to argue for a technical effect if the output provides information on an internal state of operation of a device (at the operating system level or below, e.g. battery level, processing unit utility etc.) or if the output improves a sequence of interactions with a user (e.g. provides a new way of operating a device). Again, a technical problem needs to be demonstrated and the machine learning algorithm needs to be a tool to solve this problem.
Subfields of ML and AI
In certain subfields of machine learning and artificial intelligence, there is a tendency for Boards of Appeal and Examining Divisions to consider inventions more or less “technical”. This is often for a combination of factors, including field of operation of appellants, the history of research and traditional applications, and the background and public policy preferences of staff of the European Patent Office.
For example, machine learning and artificial intelligence systems in the field of image, video and audio processing are more likely to be found to have “technical” features that can contribute to an inventive step under Article 56 EPC. A convolutional neural network architecture applied to image processing is more likely to be considered a “technical” contribution that the same architecture applied to text processing. Similarly, it may be argued that machine learning and artificial intelligence systems in the field of medicine and biochemistry have “technical” characteristics, e.g. if they operate on data originating from mass spectrometry or medical imaging.
However, advances in search, classification and natural language processing are more likely to be found to have “non-technical” features that cannot contribute to an inventive step under Article 56 EPC. These areas of machine learning and artificial intelligence systems are often felt to be “technical” by the engineers and developers building such systems. However, it is a nuance of European case law that these areas are often deemed to have claim features that fall into an excluded “business”, “mathematical” or “administrative” category.
A recent example may be found in case T 1358/09. The claim in this case comprised “text documents, which are digitally represented in a computer, by a vector of n dimensions, said n dimensions forming a vector space, whereas the value of each dimension of said vector corresponds to the frequency of occurrence of a certain term in the document”. The Board agreed with the appellant that the steps in the claim were different to those applied by a human being performing classification. However, the Board concluded that the algorithm underlying the method the claim did not “go beyond a particular mathematical formulation of the task of classifying documents”. They were of the opinion that the skilled person would have been given the (“non-technical”) text classification algorithm and simply be tasked with implementing it on a computer.
What Should We Not Do?
Managers and executives of commercial enterprises are often habituated into selling innovations to a non-technical audience. This means that invention disclosures often describe the invention at an abstract “marketing” level. When an invention is described in a patent application at this level, inventive step objections are likely.
The fact that mathematical formulae may comprise excluded “non-technical” features is difficult for inventors and practitioners to grasp. Often equations at an academic-publication level are included in patent specifications in an attempt to add technical character. This often backfires. While such equations may be deemed “technical” according to a standard definition of the term, they are often not deemed “technical” according to the definition applied by European case law.
In general, objections are more likely in this area when the scope of the claim is broad and attempts to cover applications of a particular algorithm in all industries. Applicants should be advised that trying to cover everything will likely lead to refusal.
What Should We Do?
Chances of grant may be increased by ensuring an examiner or Board of Appeal member can clearly see the practical application of the algorithm to a specific field or low-level technical area.
Patent attorneys drafting patent applications for machine learning and artificial intelligence systems should carefully consider the framing and description of the invention in the patent specification. In-depth discussions with the engineers and developers that are implementing the systems often enable innovations to be described more precisely. Given this precision, innovations may be framed as a “technical” or engineering innovation, i.e. a technical solution to a technical problem. This increases the chance of a positive opinion from the European Patent Office.
Often features of an invention will have both a business advantage and a “technical” advantage. For example, a machine learning system that learns how to dynamically route data over a network may help an online merchant more successfully route traffic to their website; however, this improved method may involve manipulation of data packets within a router that also improves network security. A patent specification describing the latter advantage will have a greater chance of grant than the former, regardless of the actual provenance of the invention. A practitioner may work with an inventor to ensure that initial business advantages are distilled to their proximate “technical” advantages and effects. For cases where data does not relate to a low-level recording or capture of a physical phenomenon, it is recommended to ensure that any described technical effect applies regardless of the content of the data.
When considering exclusion for “mental acts”, a risk of a “non-technical” objection may be reduced by ensuring that your method steps exclude a manual implementation. Note that this exclusion does not necessarily prevent other objections being raised (see T 1358/09 above).
When drafting patent applications, it is also important to describe the implementation of any mathematical method. In this manner, pseudo-code is often more useful than equations. It is also important to clearly define how attributes of the physical world are represented within the computer. Good questions to ask include: “What data structures and function routines are used to implement the elements of any equation?”, “How is data initially recorded, e.g. are documents a scanned image such as a bitmap or a markup file using a Unicode encoding?”, “What programming languages and libraries are being used?”, or “What application programming interfaces are important?”.
Practitioners do need to be concerned with including overly limiting definitions within the claims; however, a positive opinion is more likely when specific implementation examples are described in the patent specification, followed by possible generalisations, than when specific implementation examples are omitted and the description only presents a generalised form of the invention along with more detailed mathematical equations.
To be successful in search, classification and natural language processing, one approach is to determine whether features relating to a non-obvious technical implementation may be claimed. This approach often goes hand in hand with a knowledge of academic publications in the field. While such publications may disclose a version of an algorithm being used, they often gloss over the technical implementation (unless the underlying source code is released on GitHub). For example, is there any feature of the data, ignoring its content, which makes implementation of a given equation problematic? If inventors have managed to reduce the dimensionality of a neural network using clever string pre-processing or quantisation then there may be an argument that the resultant solution is implementable on mobile and embedded devices. Reducing a size of a model from 3 GB to 300 KB by intelligent selection of pipeline stages may enable you to argue for a technical effect.
Do Not Believe The Hype?
Despite the hype, machine learning and artificial intelligence systems are just another form of software solution. As such, all the general guidance and case law on computer-implemented inventions continues to apply. A benefit of the longer timescales of patent prosecution is that you ride out the waves of Gartner’s hype cycle. In fact, I still sometimes prosecute cases from the end of the dotcom boom…
Natural Language Processing and Deep Learning have the potential to overhaul patent operations for large patent departments. Jobs that used to cost hundreds of dollars / pounds per hour may cost cents / pence. This post looks at where I would be investing research funds.
The Path to Automation
In law, the path to automation is typically as follows:
Group of Patent Documents > Summary Clusters (Text or Image) (Landscaping)
Official Communication > Response Letter Text (Prosecution)
Caveat
I know there is a lot of hype out there and I don’t particularly want to be responsible for pouring oil on the flames of ignorance. I have tried to base these thoughts on widely reviewed research papers. The aim is to provide more a piece of informed science fiction and to act as a guide as to what may be. (I did originally call it “Your Patent Department 2020” :).
Many of these things discussed below are still a long way off, and will require a lot of hard work. However, the same was said 10 years ago of many amazing technologies we now have in production (such as facial tagging, machine translation, virtual assistants, etc.).
Examples
Let’s dive into some examples.
Search
At the moment, patent drafting typically starts as follows: receive invention disclosure, commission search (in-house or external), receive search results, review by attorney, commission patent draft. This can take weeks.
Instead, imagine a world where your inventors submit an invention disclosure and within minutes or hours you receive a report that tells you the most relevant existing patent publication, highlights potentially novel and inventive features and tells you whether you should proceed with drafting or not.
The techniques already exist to do this. You can download all US patent publications onto a hard disk that costs $75. You can convert high-dimensionality documents into lower-dimensionality real vectors (see https://radimrehurek.com/gensim/wiki.html or https://explosion.ai/blog/deep-learning-formula-nlp). You can then compute distance metrics between your decomposed invention disclosure and the corpus of US patent publications. Results can be ranked. You can use a Long Short Term Memory (LSTM) decoder (see https://www.tensorflow.org/tutorials/seq2seq) on any difference vector to indicate novel and possibly inventive features. A neural network classifier trained on previous drafting decisions can provide a probability of proceeding based on the difference results.
Drafting
A draft patent application in a complicated field such as computing or electronics may take a qualified patent attorney 20 hours to complete (including iterations with inventors). This process can take 4-6 weeks.
Now imagine a world where you can generate draft independent claims from your invention disclosure and cited prior art at the click of a button. This is not pie-in-the-sky science fiction. State of the art systems that combine natural language processing, reinforcement learning and deep learning can already generate fairly fluid document summaries (see https://metamind.io/research/your-tldr-by-an-ai-a-deep-reinforced-model-for-abstractive-summarization). Seeding a summary based on located prior art, and the difference vector discussed above, would generate a short set of text with similar language to that art. Even if the process wasn’t able to generate a perfect claim off the bat, it could provide a rough first draft to an attorney who could quickly iterate a much improved version. The system could learn from this iteration (https://deepmind.com/blog/learning-through-human-feedback/) allowing it to improve over time.
Or another option: how about your patent figures are generated automatically based on your patent claims and then your detailed description is generated automatically based on your figures and the invention disclosure? Prototype systems already exist that perform both tasks (see https://arxiv.org/pdf/1605.05396.pdf and http://cs.stanford.edu/people/karpathy/deepimagesent/).
Prosecution
In the old days, patent prosecution involved receiving a letter from the patent office and a bundle of printed citations. These would be processed, stamped, filed, carried around on an internal mail wagon and placed on a desk. More letters would be written culminating in, say, a written response and a set of amendments.
From this, imagine that your patent office post is received electronically, then automatically filed and docketed. Citations are also automatically retrieved and filed. Objection categories are extracted automatically from the text of the office action and the office action is categorised with a percentage indicating the chance of obtaining a granted patent. Additionally, the text of the citations is read and a score is generated indicating whether the citations remove novelty from your current claims (this is similar to the search process described above, only this time you know what documents you are comparing). If the score is lower than a given threshold, a set of amendment options are presented, along with a percentage chances of success. You select an option, maybe iterate the amendment, and then the system generates your response letter. This includes inserting details of the office action you are replying to (specifically addressing each objection that is raised), automatically generating passages indicating basis in the text of your application, explains the novel features, generates a problem-solution that has a basis in the text of your application, and provides pointers for why the novel features are not obvious. Again you iterate then file online.
Parts of this are already in place at major law firms (e.g. electronically filing and docketing). I have played with systems that can extract the text from an office action PDF and automatically retrieve and file documents via our document management application programming interface. With a set of labelled training data, it is easy to build an objection classification system that takes as input a simple bag of words. Companies such as Lex Machina (see https://lexmachina.com/) already crunch legal data to provide chances of litigation success; parsing legal data from say the USPTO and EPO would enable you to build a classification system that maps the full text of your application, and bibliographic data, to a chance of prosecution success based on historic trends (e.g. in your field since the 1970s). Vector-space representations of documents allow distance measures in n-dimensional space to be calculated, and decoder systems can translate these into the language of your specification. The lecture here explains how to create a question answering system using natural language processing and deep learning (http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_11_question_answering.mp4). You could adapt this to generate technical problems based on document text, where the answer is bound to the vector-space distance metric. Indeed, patent claim space is relatively restricted (it is, at heart, a long sentence, where amendments are often additional sub-phrases of the sentence that are consistent with the language of the claimset); the nature of patent prosecution and added subject matter, naturally produces a closed-form style problem.
Imagining Reality is the First Stage to Getting There
There is no doubt that some of these scenarios will be devilishly hard to implement. It took nearly two decades to go from paper to properly online filing systems. However, prototypes of some of these solutions could be hacked up in a few months using existing technology. The low hanging fruit alone offers the potential to shave hundreds of thousands of dollars from patent prosecution budgets.
I also hope that others are aiming to get there too. If you are please get in touch!
Playing around with natural language processing has given me the confidence to attempt some claim language modelling. This may be used as a claim drafting tool or to process patent publication data. Here is a short post describing the work in progress.
Here, a caveat: this modelling will be imperfect. There will be claims that cannot be modelled. However, our aim is not a “perfect” model but a model whose utility outweighs its failings. For example, a model may be used to present suggestions to a human being. If useful output is provided 70% of the time, then this may prove beneficial to the user.
To start we will keep it simple. We will look at system or apparatus claims. As an example we can take Square’s payment dongle:
1. A decoding system, comprising:
a decoding engine running on a mobile device, the decoding engine in operation decoding signals produced from a read of a buyer’s financial transaction card, the decoding engine in operation accepting and initializing incoming signals from the read of the buyer’s financial transaction card until the signals reach a steady state, detecting the read of the buyer’s financial transaction card once the incoming signals are in a steady state, identifying peaks in the incoming signals and digitizing the identified peaks in the incoming signals into bits;
and
a transaction engine running on the mobile device and coupled to the decoding engine, the transaction engine in operation receiving as its input decoded buyer’s financial transaction card information from the decoding engine and serving as an intermediary between the buyer and a merchant, so that the buyer does not have to share his/her financial transaction card information with the merchant.
Let’s say a claim consists of “entities”. These are roughly the subjects of claim clauses, i.e. the things in our claim. They may appear as noun phrases, where the head word of the phrase is modelled as the core “entity”. They may be thought of as “objects” from an object-oriented perspective, or “nodes” in a graph-based approach.
In the above claim, we have core entities of:
“a decoding system”
“a decoding engine”
“a transaction engine”
An entity may have “properties” (i.e. “is” something) or may have other entities (i.e. “have” something).
In our example, the “decoding system” has the “decoding engine” and the “transaction engine” as child entities. Or put another way, the “decoding engine” and the “transaction engine” have the “decoding system” as a parent entity.
In the example, the properties of the entities are more complex. The “decoding system” does not have any. It just has the child entities. The “decoding engine” “is”:
“running on a mobile device”
“in operation decoding signals produced from a read of a buyer’s financial transaction card”
“in operation accepting and initializing incoming signals from the read of the buyer’s financial transaction card until the signals reach a steady state”
“detecting the read of the buyer’s financial transaction card once the incoming signals are in a steady state”
“identifying peaks in the incoming signals and digitizing the identified peaks in the incoming signals into bits”
In these “is” properties, we have a number of implicit entities. These are not in our claim but are referred to by the claim. They are basically the other nouns in our claim. They include:
“mobile device”
“read”
“buyer’s financial transaction card”
“signals”
“peaks”
“bits”
[When modelling the part of speech tagger is mostly there but probably required human tweaking and confirmation.]
Mapping to Natural Language Processing
To extract noun phrases, we need the following processing pipeline:
claim_text > [1. Word Tokenisation] > list_of_words > [2. Part of Speech Tagging] > labelled_words > [3. Chunking] > tree_of_noun_phrases
Now, the NLTK toolkit provides default functions for 1) and 2). For 3) we have the options of a RegExParser, for which we need to supply noun phrase patterns, or Classifier-based chunkers. Both need a little extra work but there are tutorials on the Net.
Noun phrases should be used consistently throughout claim sentences – this can be used to resolve ambiguity.


























_CRUK_294.svg)